使用Computer Vision中的OCR文字辨識功能
OCR(Optical Character Recognition)指的是識別圖片中的文字,如果你先前已經成功使用Computer Vision API做影像識別(Image Analysis),那使用Computer Vision API做OCR肯定也難不倒你。
你會發現,ORC的API與先前我們介紹過的影像分析幾乎一模一樣,唯一差別是要給定的endpoint URL,最後的結尾是『ocr』。設定如下:
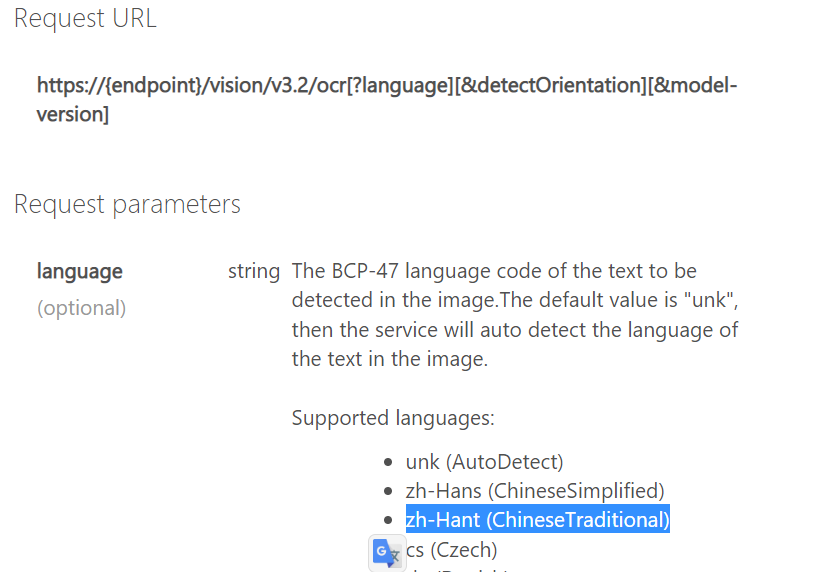
另外,如果要辨識中文,建議要給定language這個queryString參數,值為『zh-Hant』。
有這些資訊就夠了,我們一樣透過postman來測試,關鍵的資訊如下:
| 關鍵資訊 | 值 |
|---|---|
| endpoint | https://你的endpoint.cognitiveservices.azure.com/vision/v3.2/ocr?language=zh-Hant |
| Ocp-Apim-Subscription-Key(http Header) | 你的key |
| Http body | {“url”:“要辨識的圖片url”} |
透過這些,我們就可以嘗試辨識了。透過Rest API將要辨識的有像位置(url)傳遞過去,辨識的結果會以JSON回傳。
操作影片如下:
影片中,辨識的文件是底下這張圖:

該圖片的網址為:
https://i.imgur.com/PWQDiRj.png
你也可以自行試試看,你會發現,中文的辨識度其實非常高,幾乎正確的辨識出每一組文字。
回傳的物件是JSON格式,由於圖片上的文字可能有橫有直,辨識出的結果會是以 Regions, Lines, Words, Text 為結構回傳:

透過 computer Vision 中的 ocr API,取得圖片上的文字變得非常輕鬆。





留言