Azure 上的自然語言理解(natural language understanding) - 2024 年版
一直到今天,如果你去看銀行的線上客服,依舊會發現,許多所謂的AI客服,表現得都很不理想。主要的問題是大部分的AI客服對於中文語意的理解,其實都差強人意。
然而natural language understanding其實是AI Chat-Bot 乃至於 AI Agent的成功關鍵,能夠有效的識別用戶的意圖(intent),才能更進一步的幫助用戶完成所需的 action (例如請假、購票、客訴…etc.),沒有這些,就沒有後面的 AI Agent可言。
目前有哪些技術可以理解用戶所輸入的話呢?
最簡單也優秀的,當然是 LLM(大型語言模型),但由於所費不貲,所以對一般預算有限的企業來說,可能不是最終的選擇。此外,大部分優秀的LLM都沒有開源,導致使用時必須把資料(用戶的對談內容)上傳到雲端(離開國境),這對於比較嚴謹控管資安的單位,可能無法使用。
還有其他可以選擇的 語意理解 AI 服務嗎? 有的,可以考慮 Azure Language Services。
關於 Azure Language services
Azure Language Services 是微軟 Azure 提供的一系列人工智慧服務,專為處理自然語言而設計。它整合了多種功能,包括語言理解(Language Understanding)、文字內容分析、摘要、翻譯服務…等,可以幫助開發者快速建構語言驅動的應用程式。透過這些工具,企業可以輕鬆實現客戶意見分析、自動回覆系統、具有語意理解的 chat-bot及多國語言支援的應用程式…等。
建立 Azure Language Services
首先,你可以先在 Azure Portal 建立 Language 服務,過去中文版叫做文字分析,2024正名之後,終於改為『語言服務』:
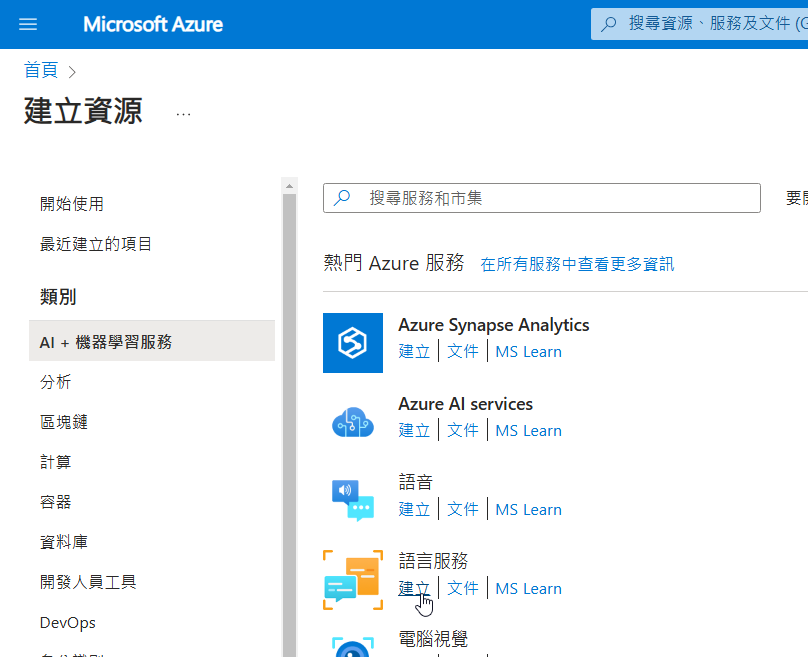
這邊直接點選左下角按鈕:
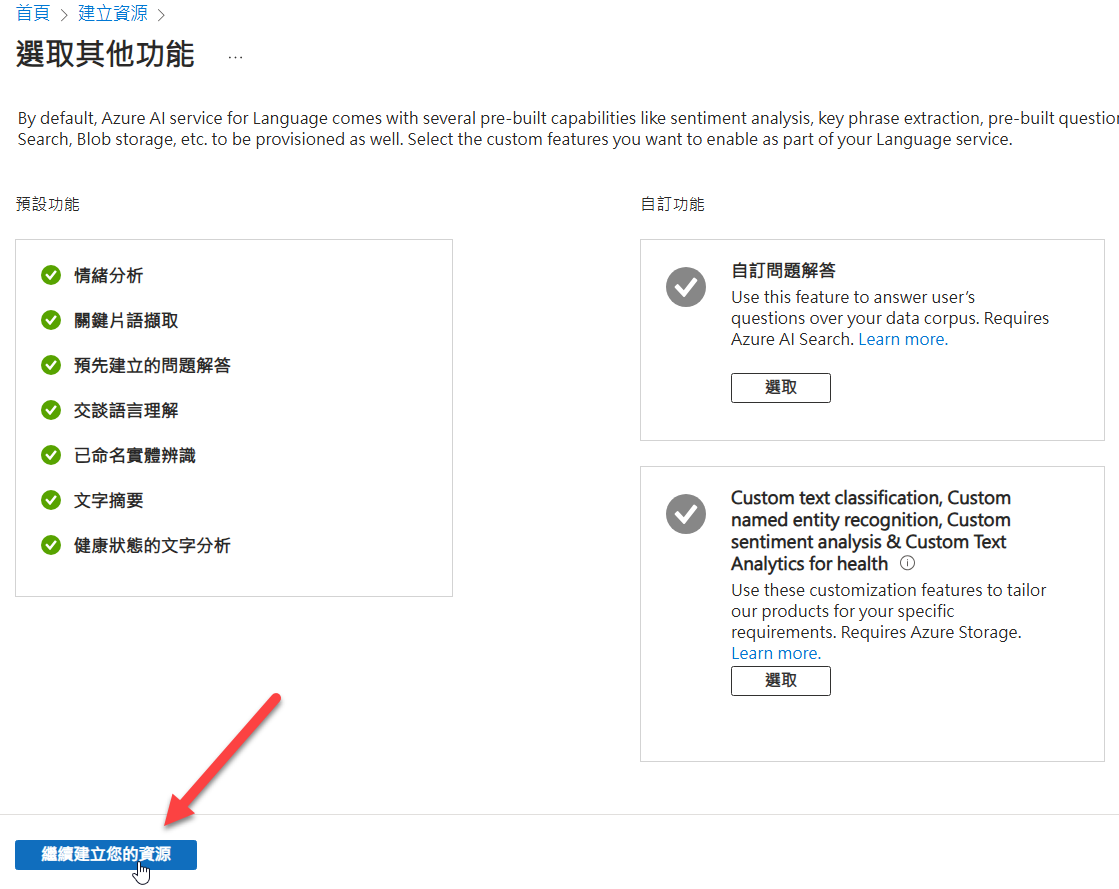
使用預設值建立即可,我建議定價層選S:
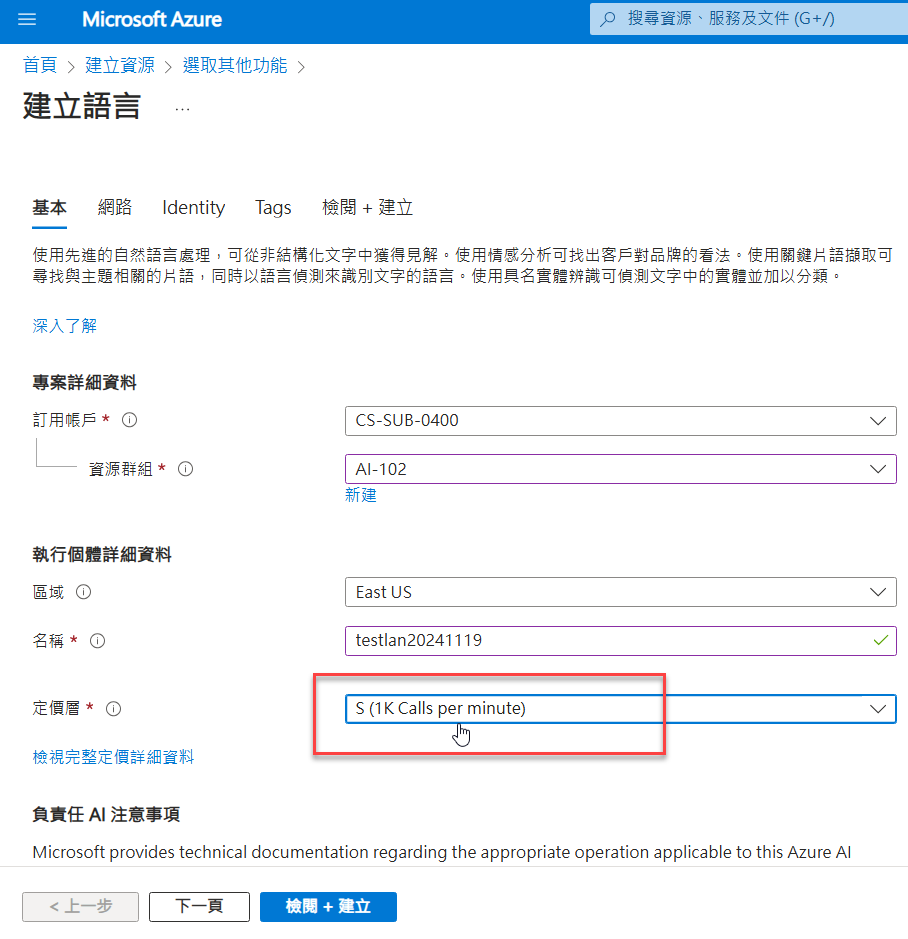
建立好之後,在服務的『概觀』底下,可以找到『Language Studio』:
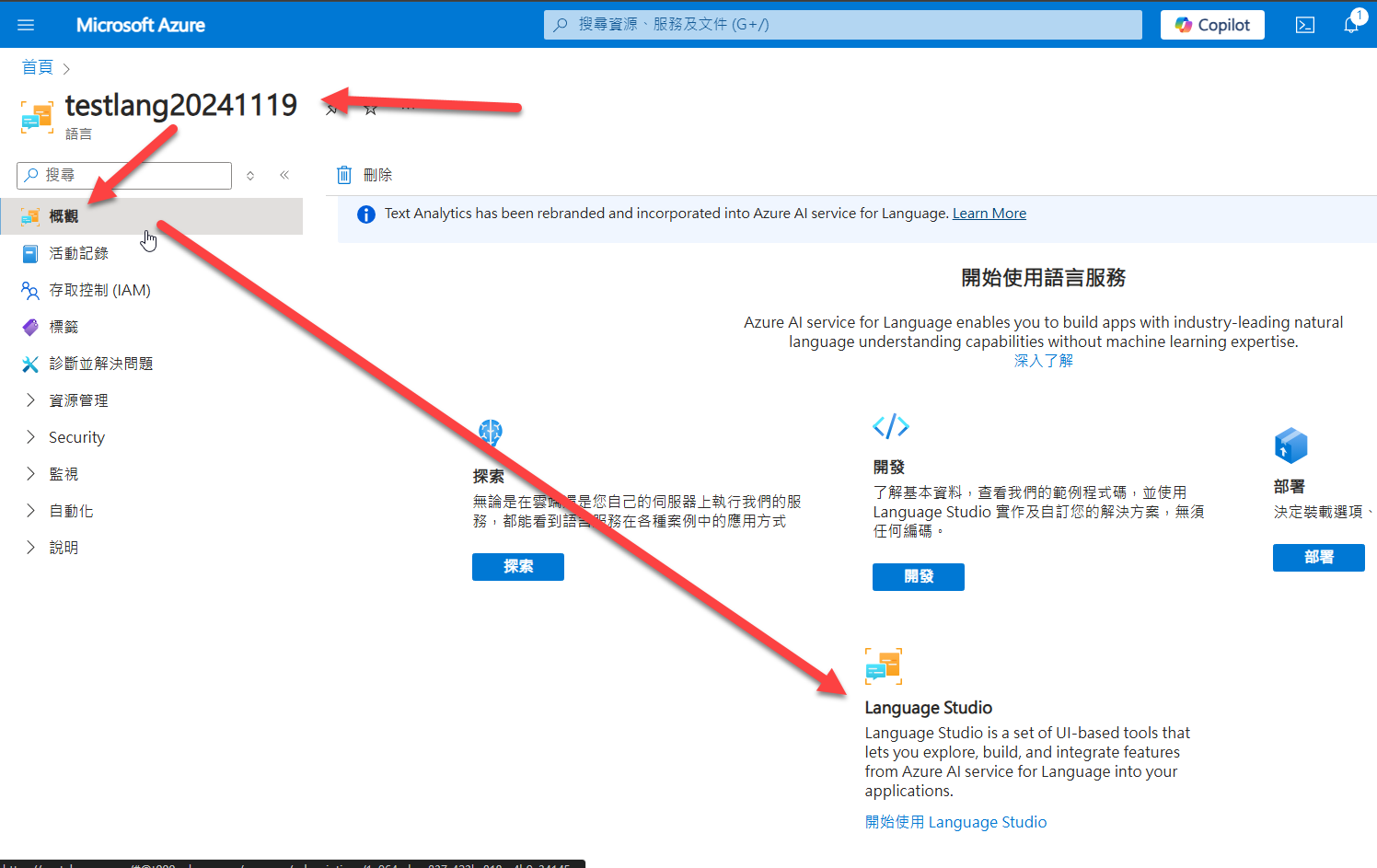
完成後,就會進入到Language Studio的主畫面:
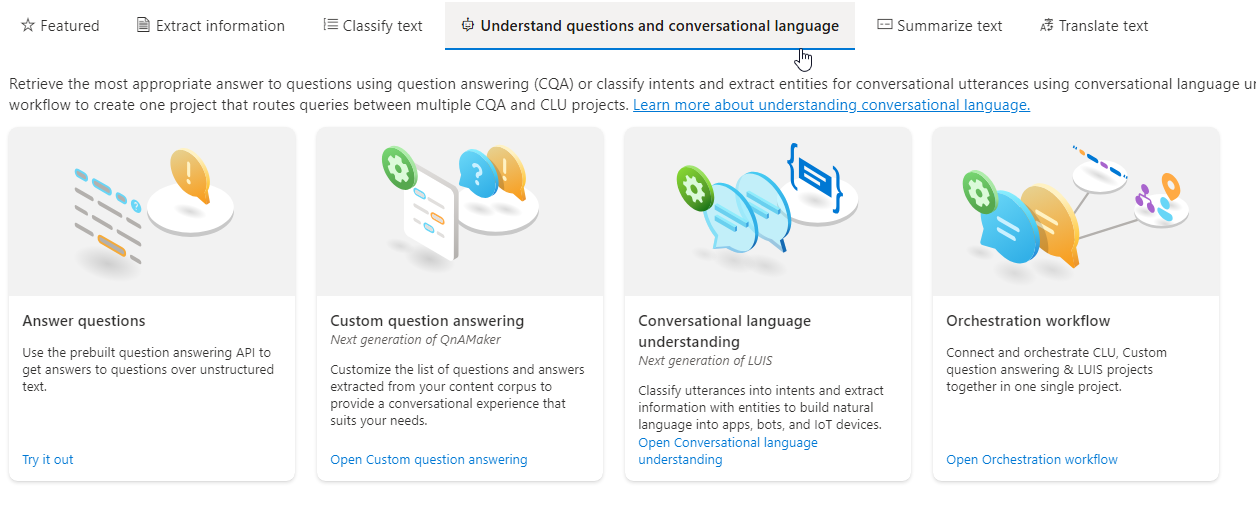
使用CLU
進入Language Studio的主畫面後,可以選擇CLU(Conversational language understanding):
接著,建立一個 app:
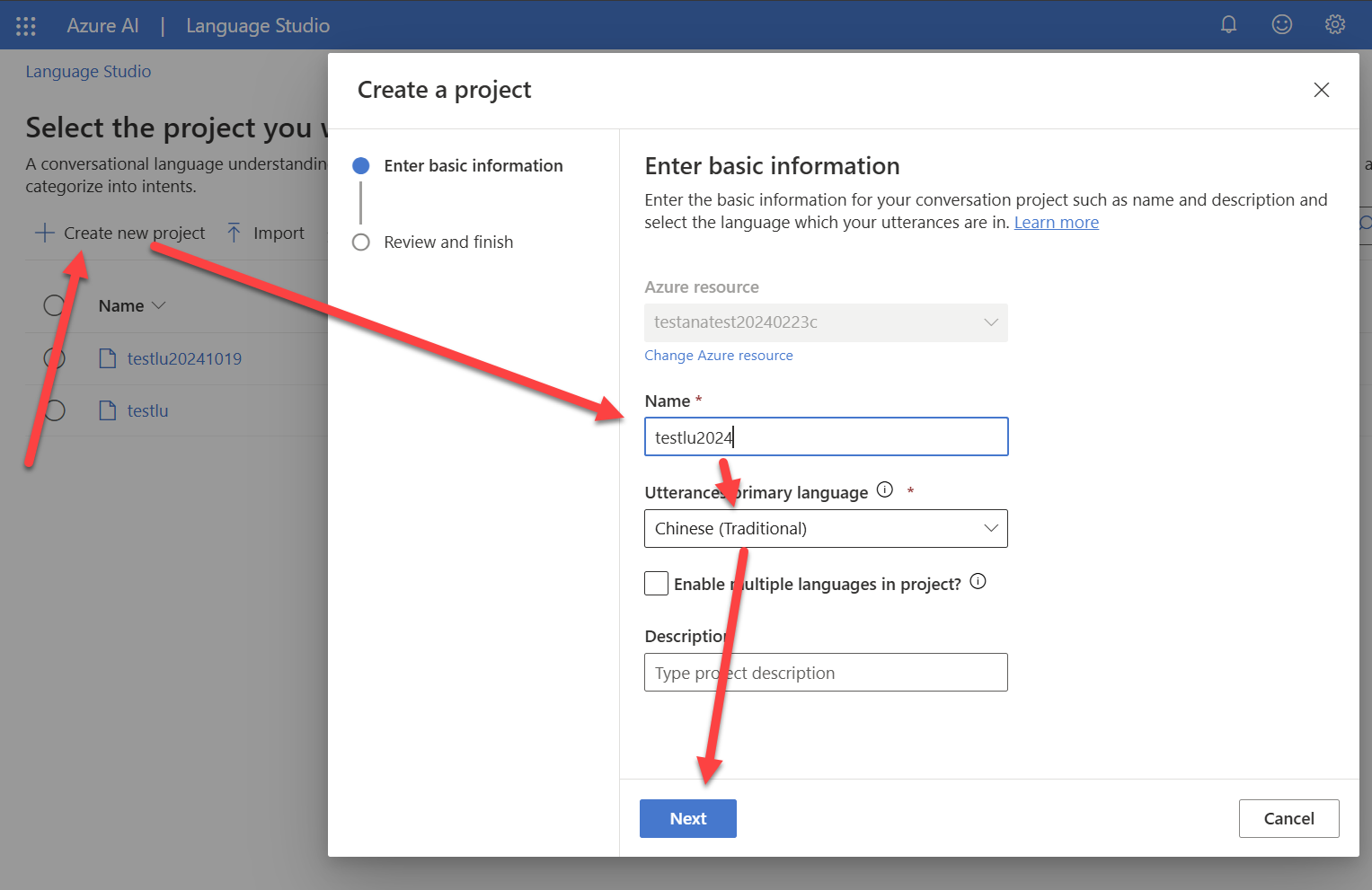
上圖中語言的部分,請務必點選中文繁體。(暫時先不建議勾選 Enabled multiple languages…)
接著,我們就可以開始建立一個模型(App)了,建立前,我們先知道一些基本觀念。
基本概念
LU的基本功能(以後有空再說複雜的),就是分析一句話,區分出用戶的意圖(Intent)和相關的Entities,我們看底下這張圖:

拿點餐這個Intent來說,如果我們要點一個早餐,用語(句型)大概會是:
- 我要點一份燒餅油條
- 麻煩你我需要一份蛋餅
- 給我來個大亨堡
- 三明治帶走
上面這四句話,基本上intent都是『客戶點餐』,而其中的Entities則是『餐點』,具體的內容(Entity Value)是燒餅油條、蛋餅、大亨堡、三明治。
而LU的目的,是幫我們在雲端分析各種不同的句型,找出用戶的意圖,並且抓出Entities。而且,由於用戶不可能只用上面這四種說法點餐,有時候可能會換成底下這樣:
今天請幫我來一個飯糰
這個句型就跟上面四種截然不同,但LU能夠從雲端大量的語料庫以及我們給的例句中,幫我們進行歸納,評估這個句型的相似性,以判斷其意圖,並抓取其中的關鍵字詞。
一開始可能判斷不對,這時人工可以介入,指導LU,讓它理解上面這個句型就是『點餐』,這樣下次LU就知道了。而其中的Entities也是,餐點種類繁多,第一次LU可能不知道有個餐點名稱叫做『飯糰』,所以它抓不出這個entity,但你可以指導它,它就知道下次在某種句型中看到飯糰,就可以將其視為entity。
而一但當我們透過LU服務,建立好了這個基礎架構之後,我們就可以用程式碼,把從bot接收到的(用戶傳來的)語句,透過API丟給雲端的LU App進行判斷,LU就會告訴我們,用戶所輸入的這個語句,其意圖Intent與Entities為何。
以便於我們的chat bot進一步就後續的回覆與處理。
好,知道了這個觀念之後,我們可以設計兩個 intent,一個是『點餐行為』,另一個是『客訴』:
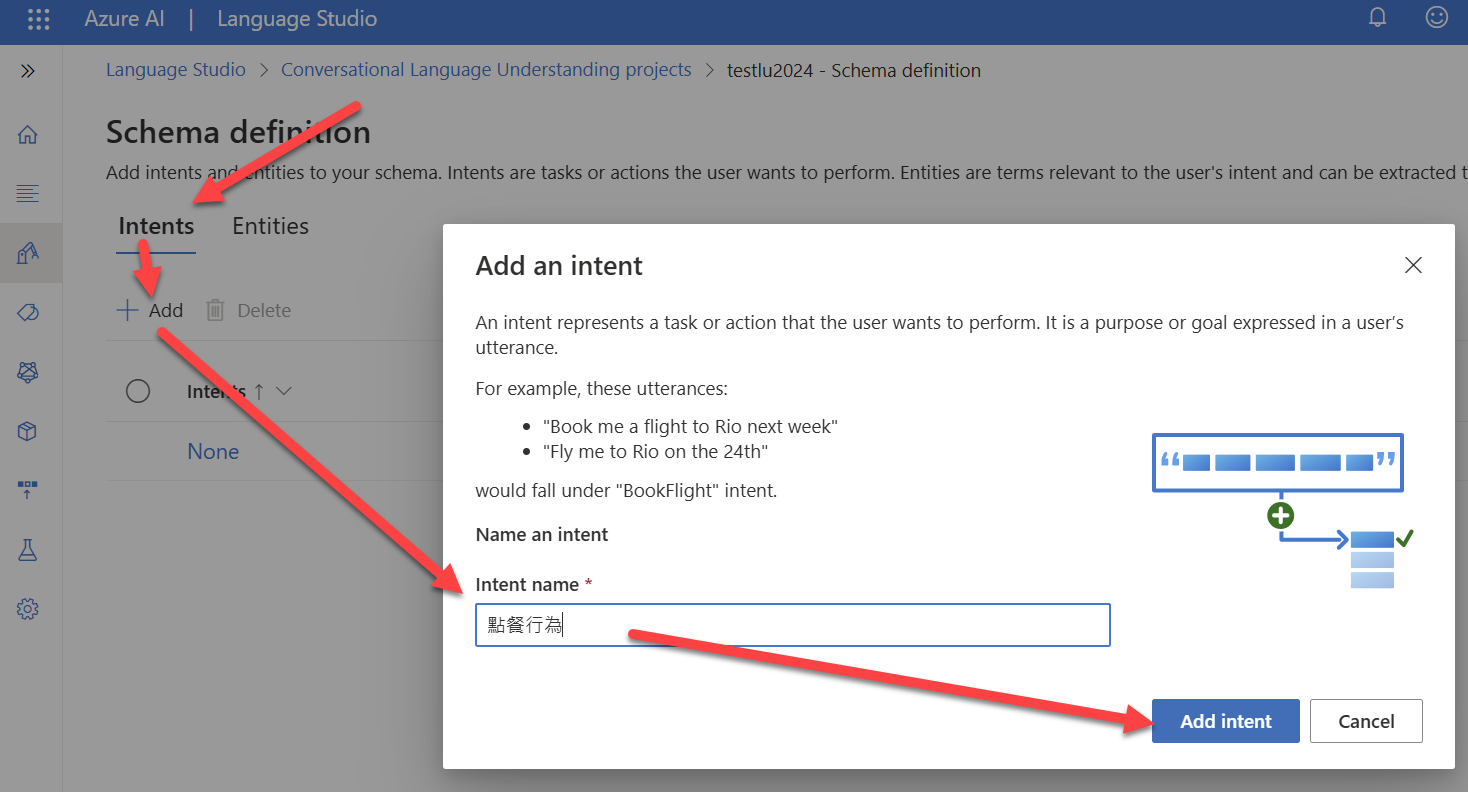
建立好之後應該像是底下這樣:
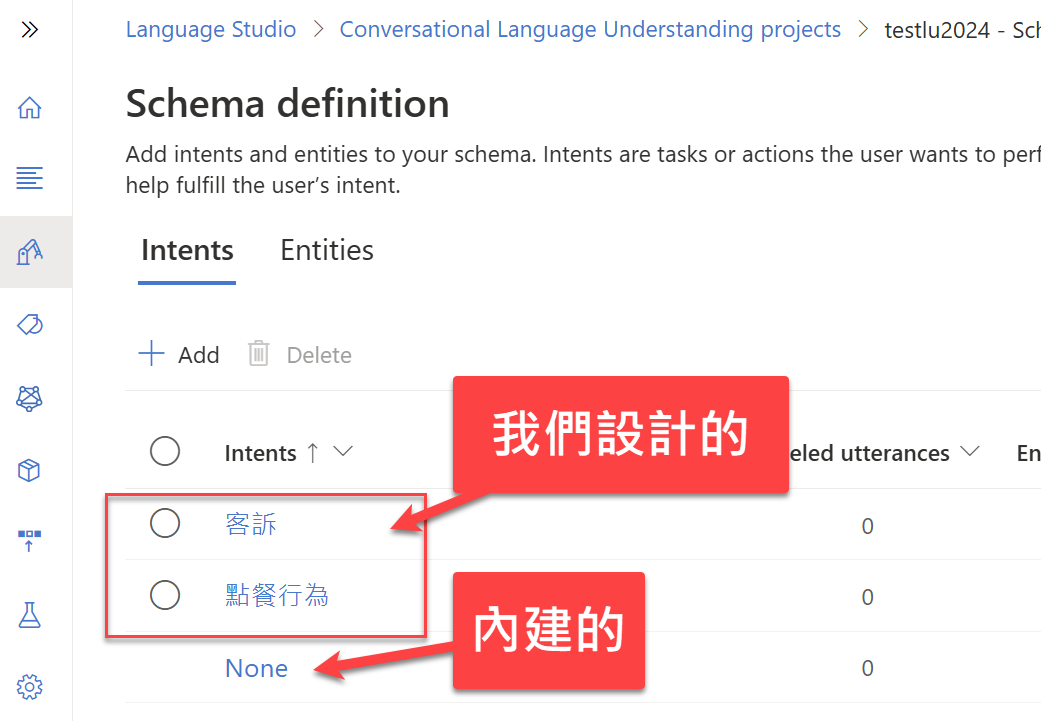
這意味著,我們可以透過這個 model 來判斷用戶所輸入的一句話是『點餐』還是『客訴』,我們的範例只有做兩個 intent,而實務上你可以依照需要建立數十個甚至上百個 intent。
而其中的預設的 None 是什麼呢? 你可以把我們的應用程式所不關注的句型,放入 None intent,它是一個系統預設的 intent,用來處理「不相關的輸入」,用來放置無法分類到其他特定 intent 的句子。
這讓它可以作為底下用途:
-
提升模型精度:
在訓練模型時,Noneintent 有助於減少誤分類的機率。你可以將一些不相關的範例語句(例如問候、閒聊、打招呼…etc.)分配給Noneintent,幫助模型更準確地學習如何區分相關(點餐、客訴)與不相關(問候…etc.)的輸入。 -
檢測未知意圖:
如果用戶輸入的內容屬於尚未定義的 intent,Noneintent 可以幫助捕捉這類輸入,並提示系統開發者是否需要擴展模型的覆蓋範圍。 -
提升使用者體驗:
在應用程式中,Noneintent 可以觸發通用的回應,告訴用戶「我不明白你的意思」,並提供一些引導性建議,例如「試試輸入 OOO」。
輸入例句
當建立好 intent 之後,接著可以為 intent 輸入例句,例如,底下這些都是點餐:
點餐語料區:
我要點一份燒餅油條
麻煩你我需要一份蛋餅
給我來個大亨堡
三明治帶走
今天請幫我來一個飯糰
今天我想要一份咔啦雞腿堡和可樂一杯
來一份炒泡麵加蛋不要辣
排骨飯加竹筍湯一份帶走
給我來一份黃金開口笑
我要一杯大珍奶微糖
今晚,我想來點…金鋒的滷肉飯加蛋。
來一份5號限定香蕉
來一碗貢丸湯加大不要貢丸
給紐妞來一份銅鑼燒早餐,我要經典紐約客早午餐
我想吃米糕便當
老闆給我來個今日特餐
給開司一罐啤酒
我們可以用底下這樣的方式輸入,並且順便建立 Entities:

注意框出 Entities 的部分,頭尾都是使用滑鼠左鍵。
至於哪些字詞要框成 Entities,則是由你自行決定,一般來說,我們在一句話中想要抓取到的關鍵字詞,都可以為它設計一個 Entities,例如上圖中的餐點名稱、飲料名稱…,又或者是購買高鐵票時的起迄站別、票種、數量、時間…等。
完成後,接著再比照同樣的模式,建立另一個 Intent 客訴:
客訴語料區:
叫你老闆出來
我不喜歡你們可樂的味道
店員服務態度不好
老闆我要的炒麵不要加辣,粥不要蔥啦
湯裡有小強
今天肉沒熟,湯很酸
服務有夠差,老板臉真臭
地很髒
空調是有沒有開拉
漢堡很難吃
牛排裡面有頭髮
地板黏黏濕濕的
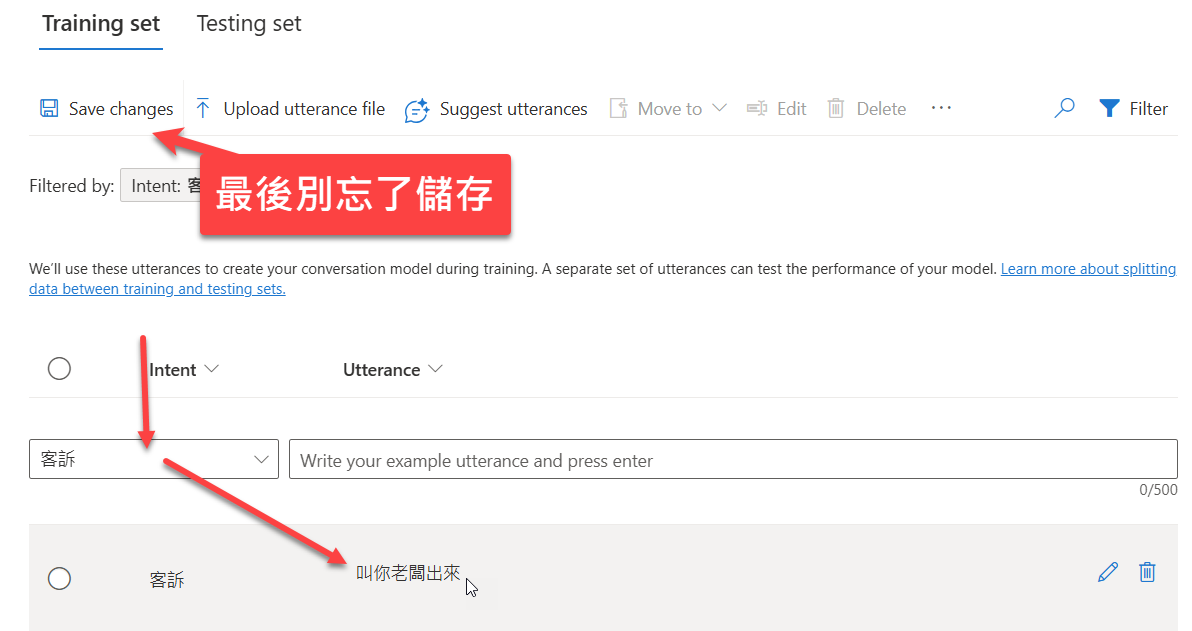
好囉,完成兩個 intent 的建立,儲存之後,接著,我們就可以訓練並發布這個模型。
請注意,系統建議每一個 intent 至少必須有 15 個例句。
訓練
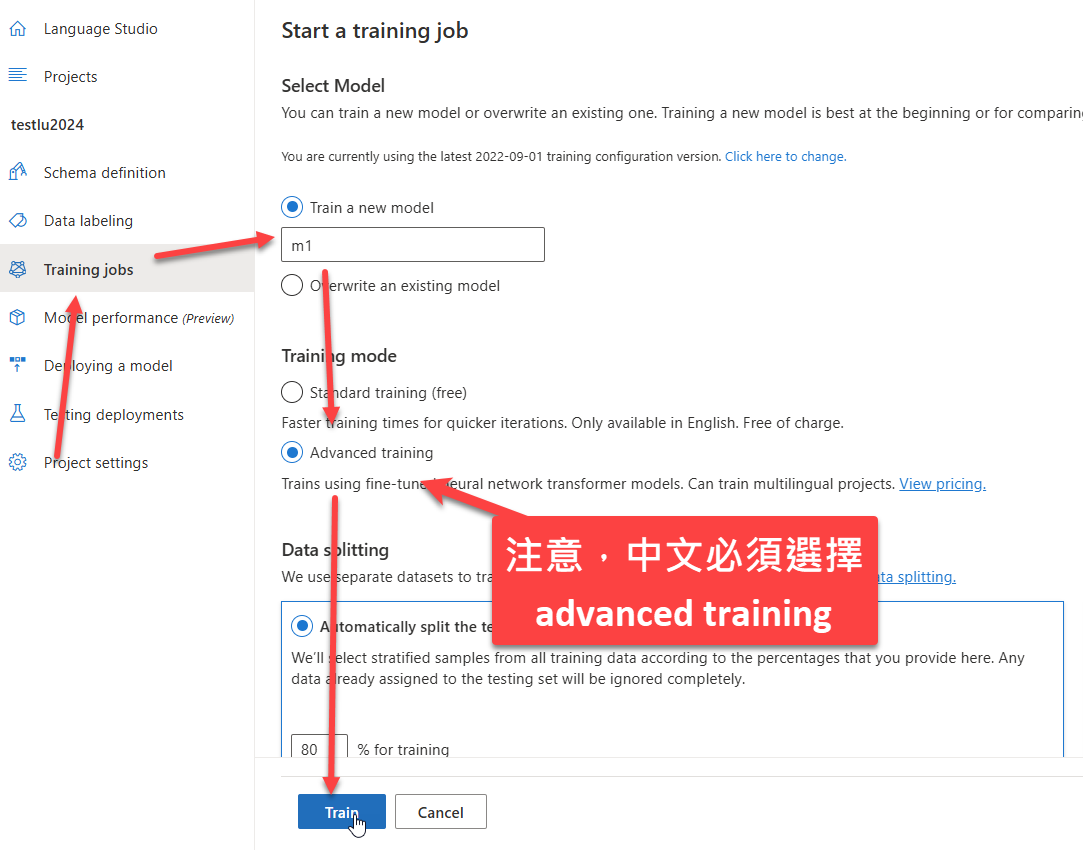
接著在左方選單中找到 Training Jobs,點選後,在出現的畫面中,輸入你自己設定的 model 名稱、選擇 training mode(建議 advanced training),完成後按下 train 按鈕即可:
你會看到右上角出現訊息與小鈴鐺:
接著就是一段等待的時間了,大概需要10-15分進行訓練(其實有接近10分鐘的時間在排隊,訓練只需要3-5分鐘時間)。
完成後,你可以從 Model performance 看到報告:
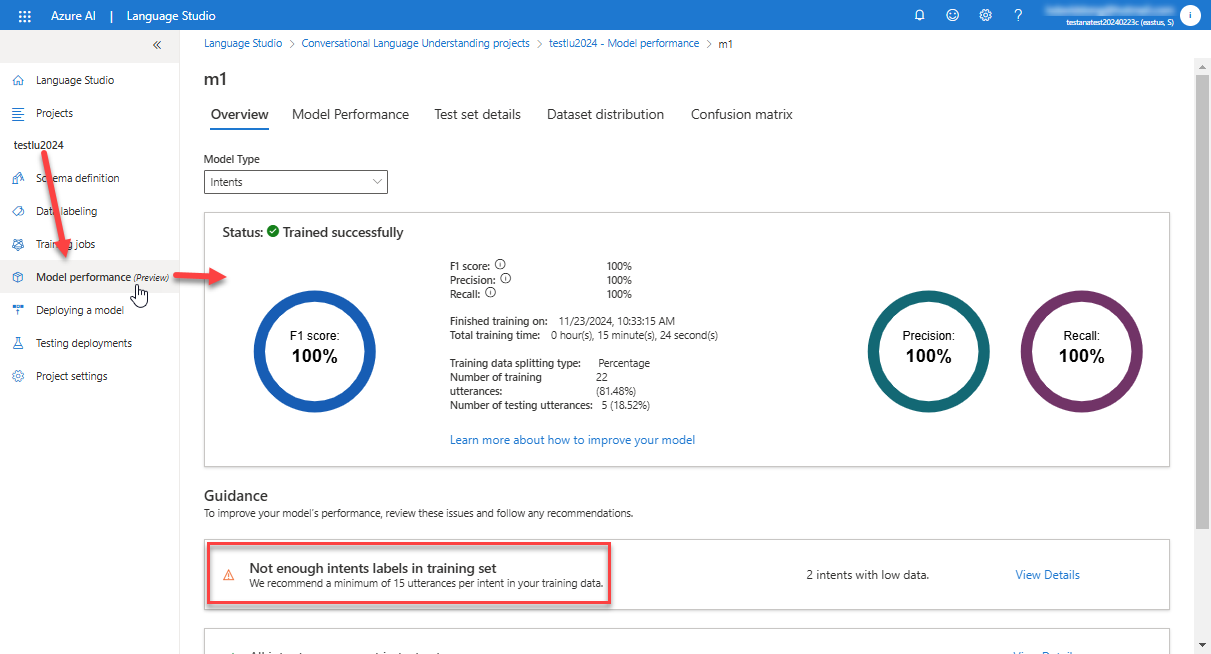
接著,就可以佈署該模型成為一個雲端服務了。你可以點選 Deploying a model:
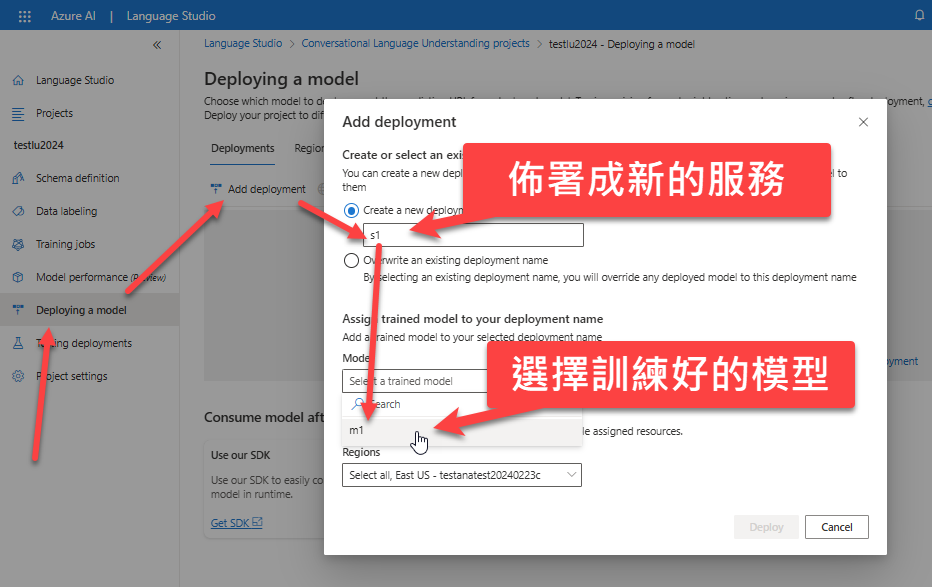
佈署完成之後,就可以透過 Get Prediction URL 找到呼叫該服務的相關資訊:
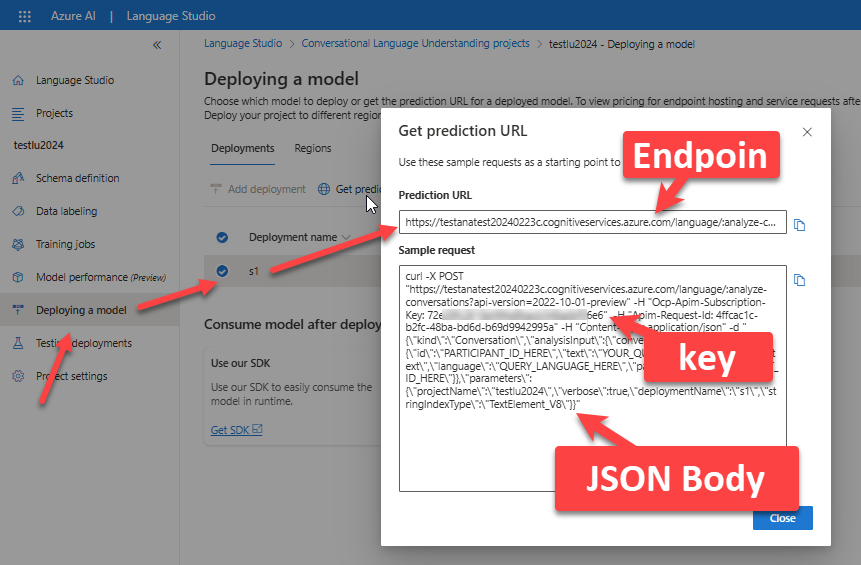
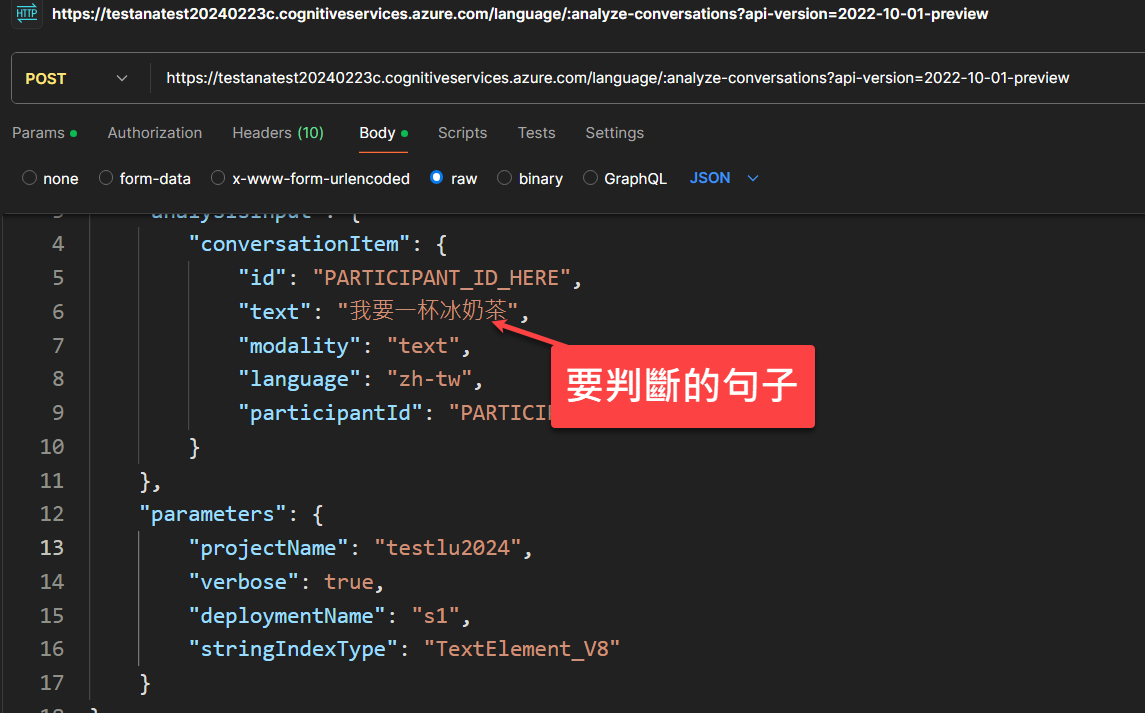
使用 postman 進行呼叫測試
找到了 model 的 endpoint 之後,我們就可以試著用程式來呼叫,我們使用 psotman 進行測試,讀者可以透過底下的 JSON Body來測試:
{
"kind": "Conversation",
"analysisInput": {
"conversationItem": {
"id": "PARTICIPANT_ID_HERE",
"text": "我要一杯冰奶茶",
"modality": "text",
"language": "zh-tw",
"participantId": "PARTICIPANT_ID_HERE"
}
},
"parameters": {
"projectName": "testlu2024",
"verbose": true,
"deploymentName": "s1",
"stringIndexType": "TextElement_V8"
}
}
你會發現,使用 postman 並在json中填入要判斷的句子,我們就可以輕易的判斷出一句話的意圖(intent),並且順便抓出其中的關鍵字詞,即便餐點名稱和飲料名稱不在原本的訓練例句中,也可以順利的找到,底下是回傳的JSON結果:
{
"kind": "ConversationResult",
"result": {
"query": "我要一杯冰奶茶",
"prediction": {
"topIntent": "點餐行為",
"projectKind": "Conversation",
"intents": [
{
"category": "點餐行為",
"confidenceScore": 0.9999804
},
{
"category": "客訴",
"confidenceScore": 1.9620242E-05
},
{
"category": "None",
"confidenceScore": 0
}
],
"entities": [
{
"category": "餐點名稱",
"text": "冰奶茶",
"offset": 4,
"length": 3,
"confidenceScore": 1
}
]
}
}
}
好啦,透過這樣的方式,我們就可以輕易的判斷一句話的意圖,如此一來,我們的 chat bot就可以更有效地協助用戶進行想要完成的動作了(不管是購物、請假、客訴、訂票、還是其他…)
以上就是 Azure Language Understanding服務的介紹。





留言