Microsoft Cognitive Services (1) - 使用Computer Vision API辨識人臉
Cognitive Services當中,我覺得最簡單好用的就是Computer Vision API。
Computer Vision ,顧名思義,它可以幫你來識別一張照片。識別什麼呢? 例如,他可以幫影像加上Tag來分類,或是描述一張影像中的內容(像是,照片中的人手上拿著一把槍),它也可以幫你辨識照片中的人臉(男性?女性?幾歲?),或是識別照片中的文字。或者,自動判斷這張照片是否為不雅照,用途非常廣泛。
我們先以最簡單的人臉識別來說好了。
雖然,Cognitive Services中有另外一組Face API可以幫你做到更細緻的功能,例如判斷照片中的人是誰,但如果你只是很簡單的想要找出照片中有多少人,那Computer Vision API 可以輕易幫你做到。
首先,請先參考先前這篇文章,使用Computer Vision API 前你必須有一個Key,最簡單的方式,就是用Microsoft Account免費申請。
取得Key之後,我們建立一個Web Application專案來試試看。請在專案中透過Nuget引用 Microsoft.ProjectOxford.Vision:
接著就可以在程式碼當中使用Computer Vision API了。使用該API的第一個動作,建立一個VisionClient:
記得建立時,要把你的VisionAPI Key傳進去。
接著,只需要透過呼叫 AnalyzeImageAsync(stream, VisualFeatures) 方法就可以分析圖片。
其中stream是圖像來源,而VisualFeature則是指定要分析圖片的那些特徵,例如,我們透過WebForm的FileUpload控制項上傳圖片,並且要分析圖片的意義與識別圖片中有多少臉,因此,程式碼如下:
分析後的結果會從Results物件回傳,因此,我們可以透過底下的程式碼來取得圖片中有多少臉,以及圖片的說明Description:
你會看到上面的程式碼當中,我們透過g (Graphics物件)幫找到的人臉繪製紅框,執行的結果大致上如下(對,半張臉它認不出來):
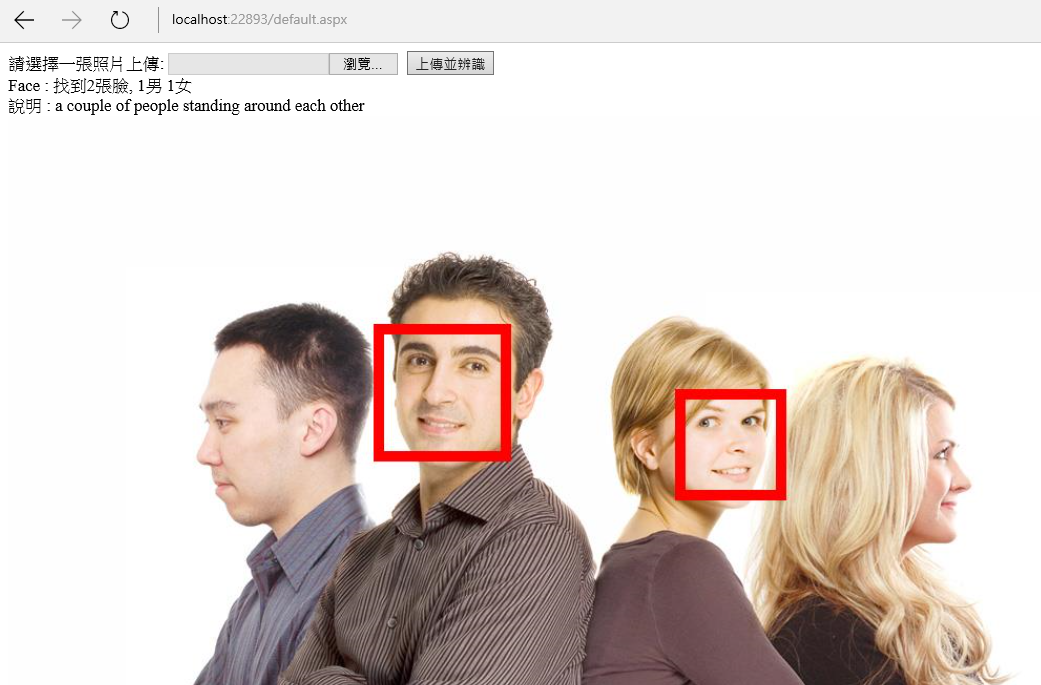
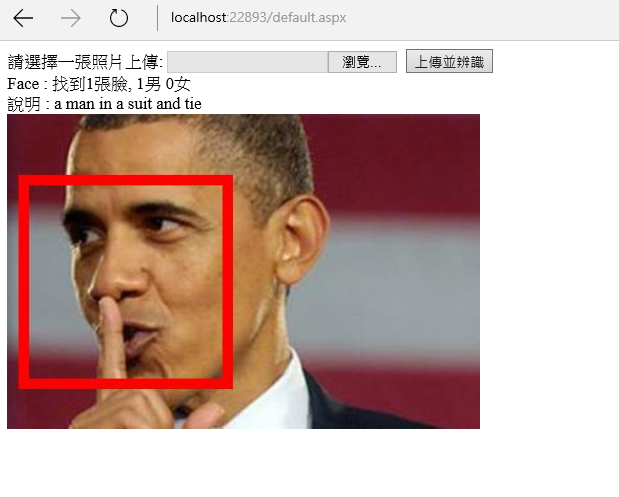
請特別留意上面兩張圖,執行結果中『說明:』後面的文字,是Computer Vision API 分析後對圖片的description,這很有趣,你會發現其實目前的辨識效果已經相當不錯,隨著大數據越來越成熟,整個辨識率的提升指日可待。
Computer Vision API 除了識別圖片中的人臉、判斷整個圖片的意義,它還可以幫我們找出圖片中的文字,也就是OCR的功能,下一篇,我們來看這個部分。
source code : https://github.com/isdaviddong/MSVisionAPI_Face_Desc/blob/master/testVisionAPI/default.aspx.cs
--------------------------------------------
線上課程:https://www.udemy.com/line-bot/
電子書:https://www.pubu.com.tw/ebook/103305
LineBotSDK:https://www.nuget.org/packages/LineBotSDK
如果需要即時取得更多相關訊息,可按這裡加入FB專頁。若這篇文章對您有所幫助,請幫我們分享出去,謝謝您的支持。
Computer Vision ,顧名思義,它可以幫你來識別一張照片。識別什麼呢? 例如,他可以幫影像加上Tag來分類,或是描述一張影像中的內容(像是,照片中的人手上拿著一把槍),它也可以幫你辨識照片中的人臉(男性?女性?幾歲?),或是識別照片中的文字。或者,自動判斷這張照片是否為不雅照,用途非常廣泛。
我們先以最簡單的人臉識別來說好了。
雖然,Cognitive Services中有另外一組Face API可以幫你做到更細緻的功能,例如判斷照片中的人是誰,但如果你只是很簡單的想要找出照片中有多少人,那Computer Vision API 可以輕易幫你做到。
首先,請先參考先前這篇文章,使用Computer Vision API 前你必須有一個Key,最簡單的方式,就是用Microsoft Account免費申請。
取得Key之後,我們建立一個Web Application專案來試試看。請在專案中透過Nuget引用 Microsoft.ProjectOxford.Vision:
接著就可以在程式碼當中使用Computer Vision API了。使用該API的第一個動作,建立一個VisionClient:
//使用Computer Vision API
var visionClient =
new Microsoft.ProjectOxford.Vision.VisionServiceClient(VisionAPIKey);
記得建立時,要把你的VisionAPI Key傳進去。
接著,只需要透過呼叫 AnalyzeImageAsync(stream, VisualFeatures) 方法就可以分析圖片。
其中stream是圖像來源,而VisualFeature則是指定要分析圖片的那些特徵,例如,我們透過WebForm的FileUpload控制項上傳圖片,並且要分析圖片的意義與識別圖片中有多少臉,因此,程式碼如下:
//分析圖片(從FileUpload1.PostedFile.InputStream取得影像)
//分析 Faces & Description
var Results = await visionClient.AnalyzeImageAsync(this.FileUpload1.PostedFile.InputStream,
new VisualFeature[] { VisualFeature.Faces, VisualFeature.Description });
分析後的結果會從Results物件回傳,因此,我們可以透過底下的程式碼來取得圖片中有多少臉,以及圖片的說明Description:
int isM = 0, isF = 0;
//列出每一個找到的臉
foreach (var Face in Results.Faces)
{
//取得人臉位置
var faceRect = Face.FaceRectangle;
//繪製人臉紅框
g.DrawRectangle(
new Pen(Brushes.Red, 10),
new Rectangle(faceRect.Left, faceRect.Top,
faceRect.Width, faceRect.Height));
//計算幾男幾女
if (Face.Gender.StartsWith("M"))
isM += 1;
else
isF += 1;
}
你會看到上面的程式碼當中,我們透過g (Graphics物件)幫找到的人臉繪製紅框,執行的結果大致上如下(對,半張臉它認不出來):
請特別留意上面兩張圖,執行結果中『說明:』後面的文字,是Computer Vision API 分析後對圖片的description,這很有趣,你會發現其實目前的辨識效果已經相當不錯,隨著大數據越來越成熟,整個辨識率的提升指日可待。
Computer Vision API 除了識別圖片中的人臉、判斷整個圖片的意義,它還可以幫我們找出圖片中的文字,也就是OCR的功能,下一篇,我們來看這個部分。
source code : https://github.com/isdaviddong/MSVisionAPI_Face_Desc/blob/master/testVisionAPI/default.aspx.cs
--------------------------------------------
線上課程:https://www.udemy.com/line-bot/
電子書:https://www.pubu.com.tw/ebook/103305
LineBotSDK:https://www.nuget.org/packages/LineBotSDK
如果需要即時取得更多相關訊息,可按這裡加入FB專頁。若這篇文章對您有所幫助,請幫我們分享出去,謝謝您的支持。





留言