在大語言模型(LLM)中使用企業內的資料
大型語言模型(LLM)雖然很好用,但在生成回應時,可能會出現「幻覺」現象,生成與事實不符的內容。此外,LLM 的知識受限於訓練資料,無法即時更新。為解決這些問題,檢索增強生成(RAG)技術常被引入,透過從外部知識庫擷取相關資訊,為模型提供最新且準確的資料。這樣可以提高用戶詢問問題時,回應的準確性,也減少了重新訓練模型的成本。但建立RAG功能往往需要一些技術能力,對一般用戶來說可能不是人人都可以實施。
因此,在 Azure OpenAI 服務中,加入了「新增您的資料」(Add Your Data)功能,允許使用者將自訂的非結構化或結構化資料(如 PDF、Word、MarkDown、純文字…等)整合到 OpenAI 模型中,以提供更具上下文相關性的回答。
這項功能透過 Azure AI Search 進行索引,並運用像是 Retrieval-Augmented Generation (RAG) 這樣的技術,在用戶詢問問題時,優先檢索事先準備好(索引過)的資料,將其作為LLM回應的基礎,以提升回應的準確性。這技術適用於知識庫QA、企業內部搜尋 及 AI 助理…等應用,無須微調模型即可實現個性化且正確的回應。
使用「新增您的資料」
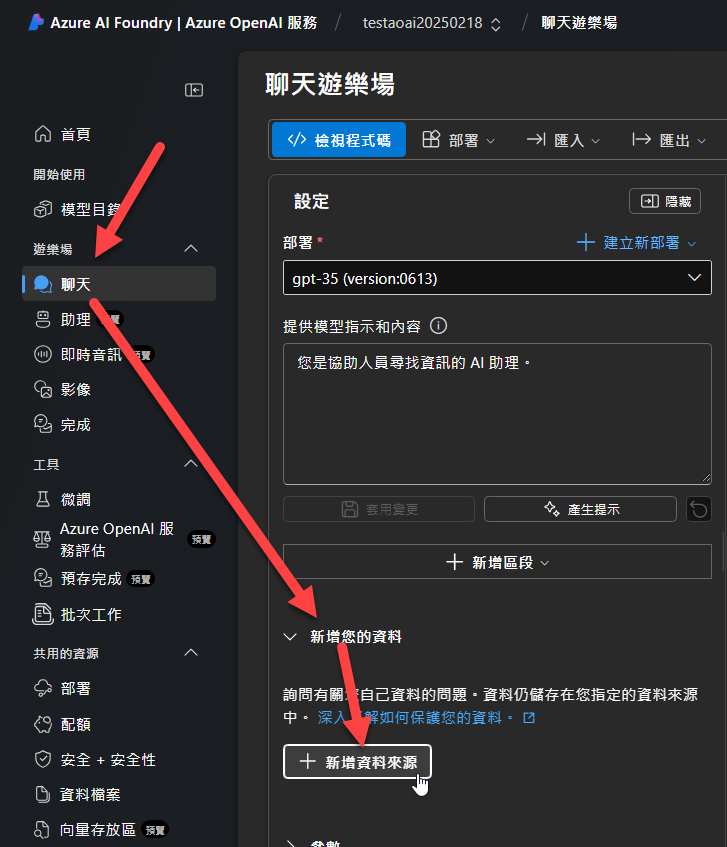
使用的方式也很簡單,當你佈署好一個AOAI的LLM模型(例如 gpt-4o)之後,可以到上圖中的聊天遊樂場,接著按下圖中「新增您的資料」按鈕,在出現的畫面上選擇Upload files:
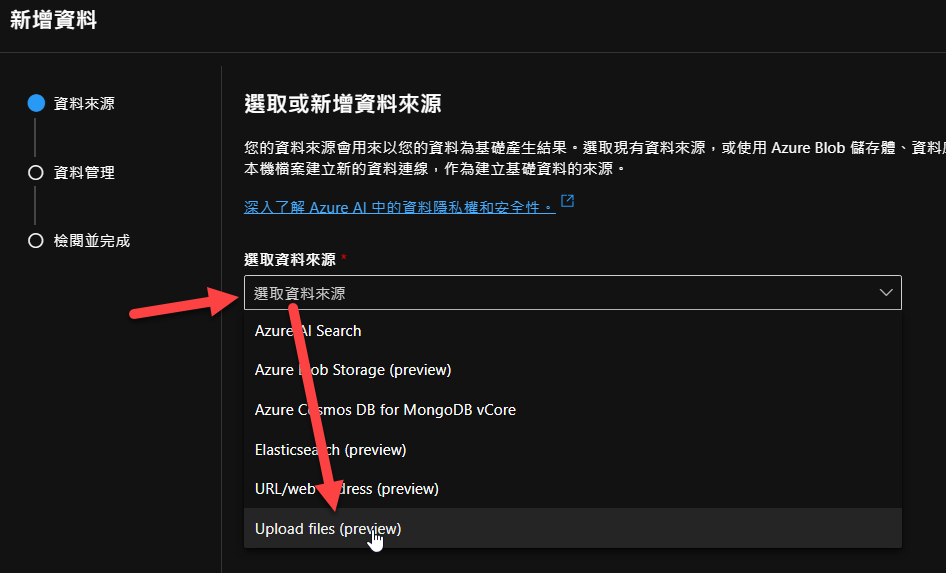
接著你會看到底下畫面,請先點選藍色的小字,建立 Azure Blob 與Azure AI Search 服務(建立時建議與AOAI佈署在同一個資料中心):
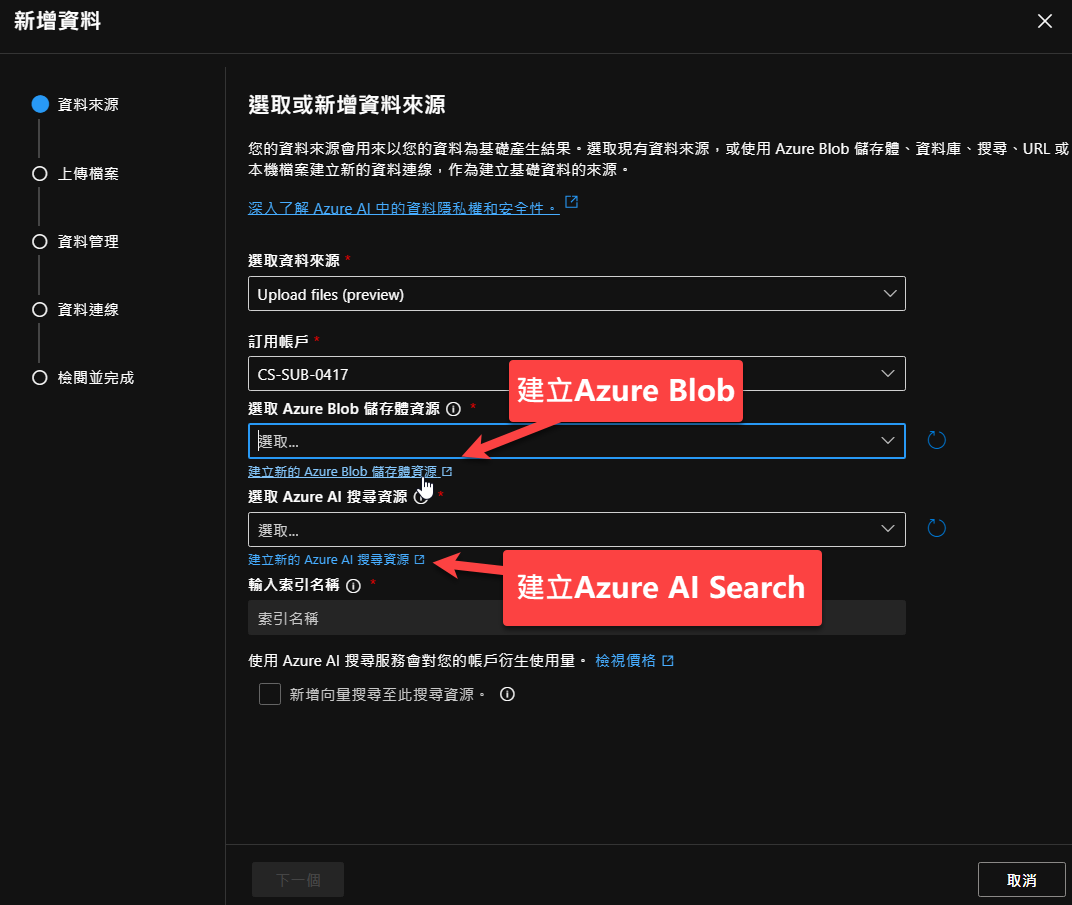
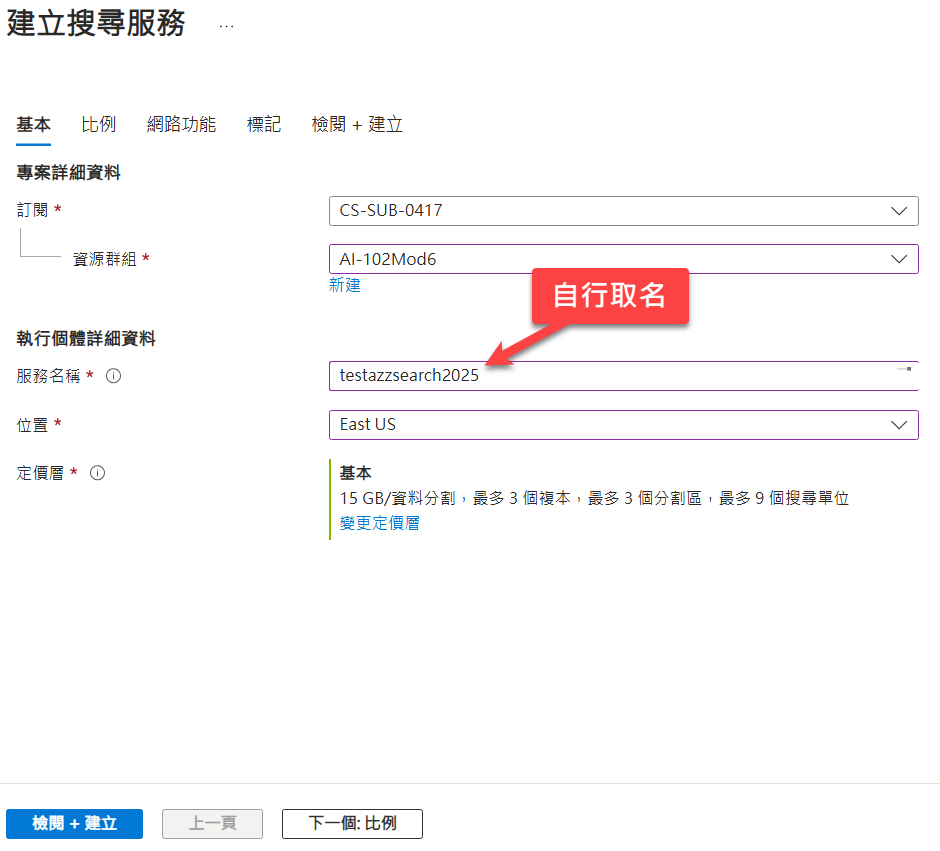
建立儲存體時,可以參考底下設定(名稱則可以自行選擇):
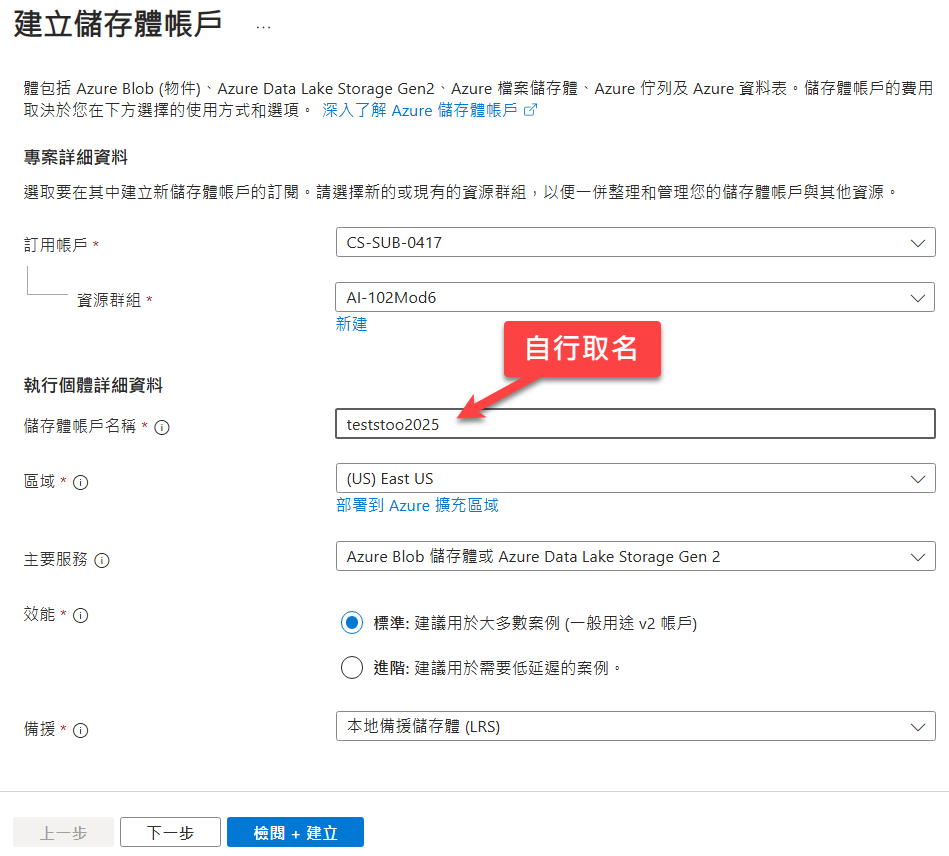
建立 Azure AI Search 服務時,則可以參考底下:
完成後,我們回到 Add Your Data 的設定畫面,請依照底下順序操作:
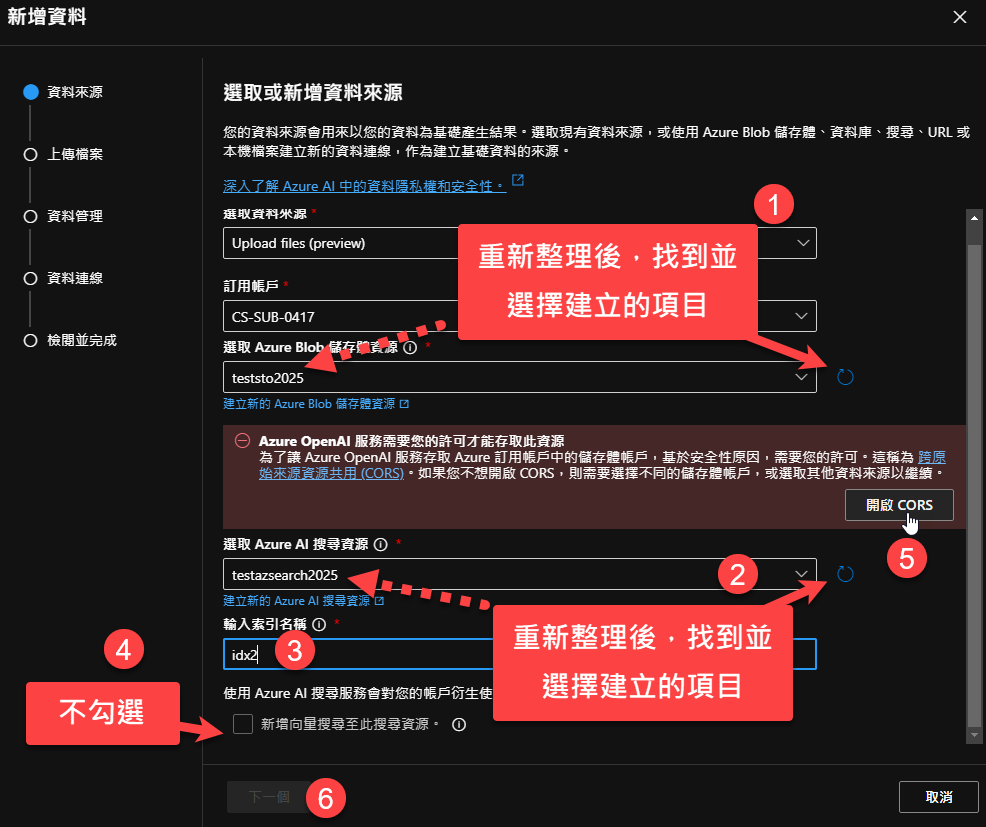
先選取 Azure Blob 與 Azure AI Search 服務,接著輸入索引名稱(可自行設定),然後暫不勾選新增向量搜尋,最後按下『開啟CORS』,成功後,會出現底下畫面:
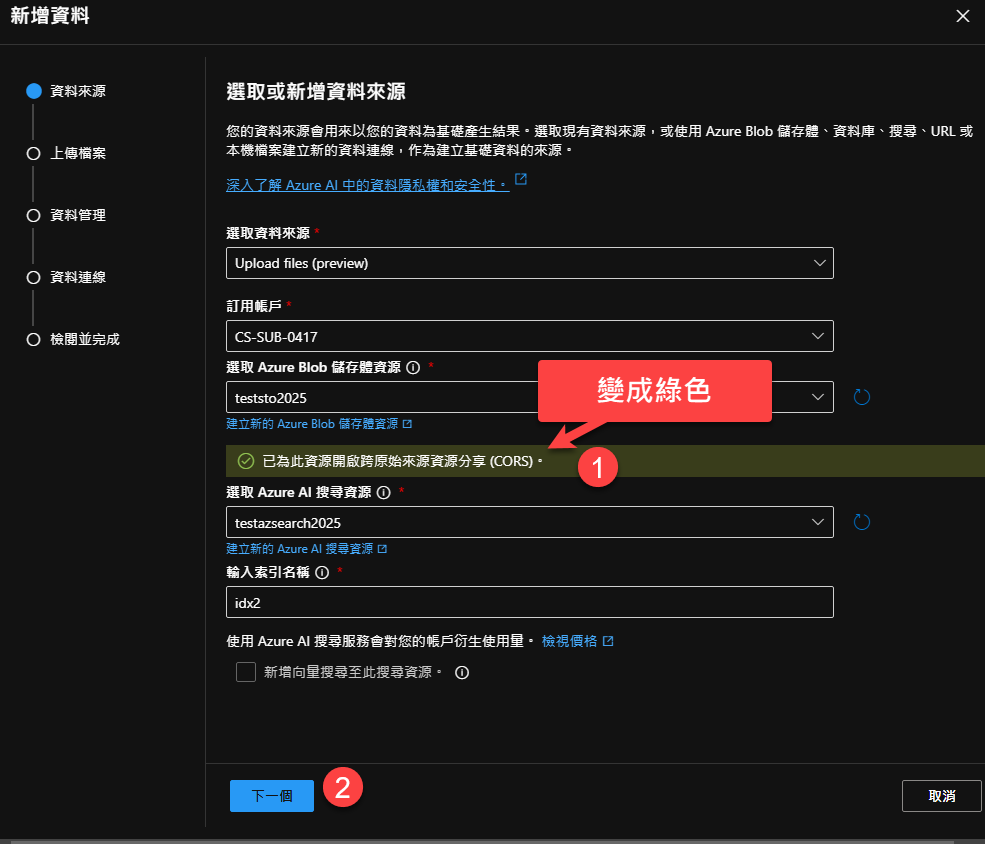
你會發現顯示的訊息變成綠色,這時候就可以按『下一個』按鈕繼續。
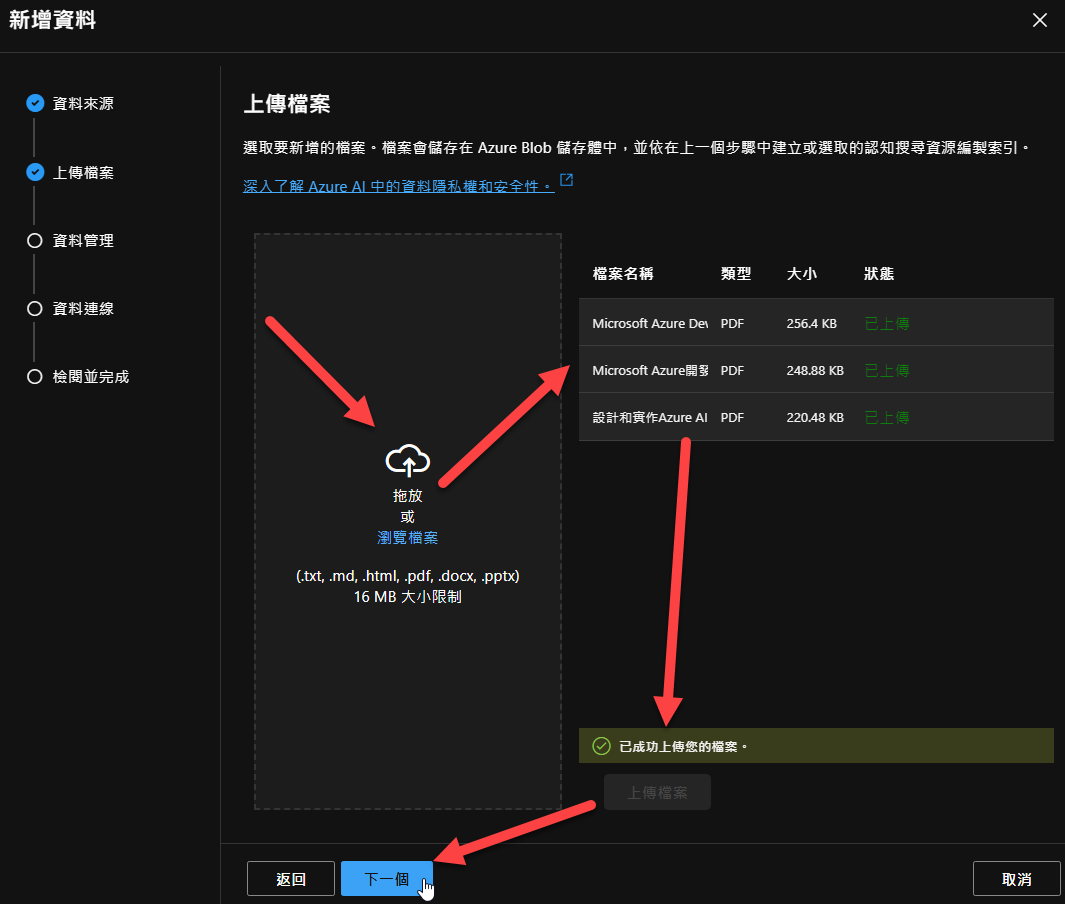
接著,你就可以在底下畫面上傳檔案(可以接受 pdf, 文字檔, docx, pptx 等多種格式…):
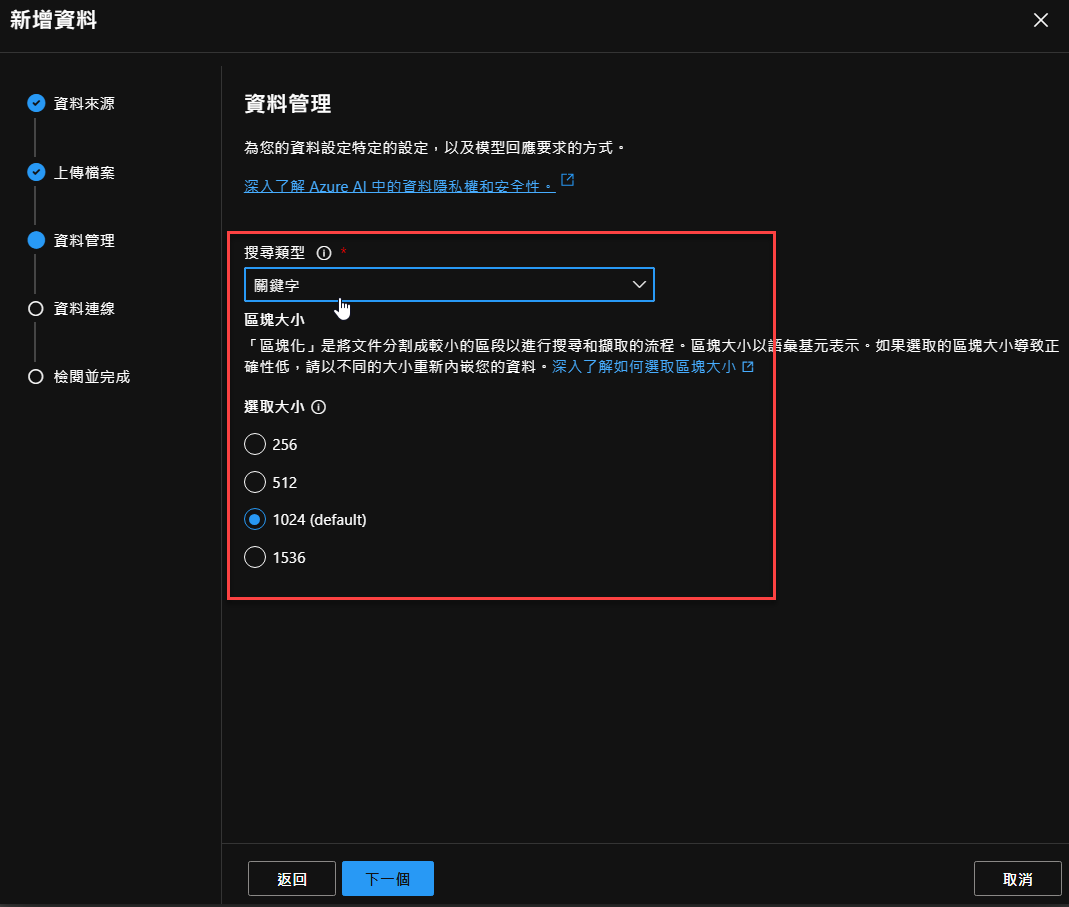
然後會出現讓你選擇搜尋類型的建立方式,我們先選擇 『關鍵字』,其他維持預設值:
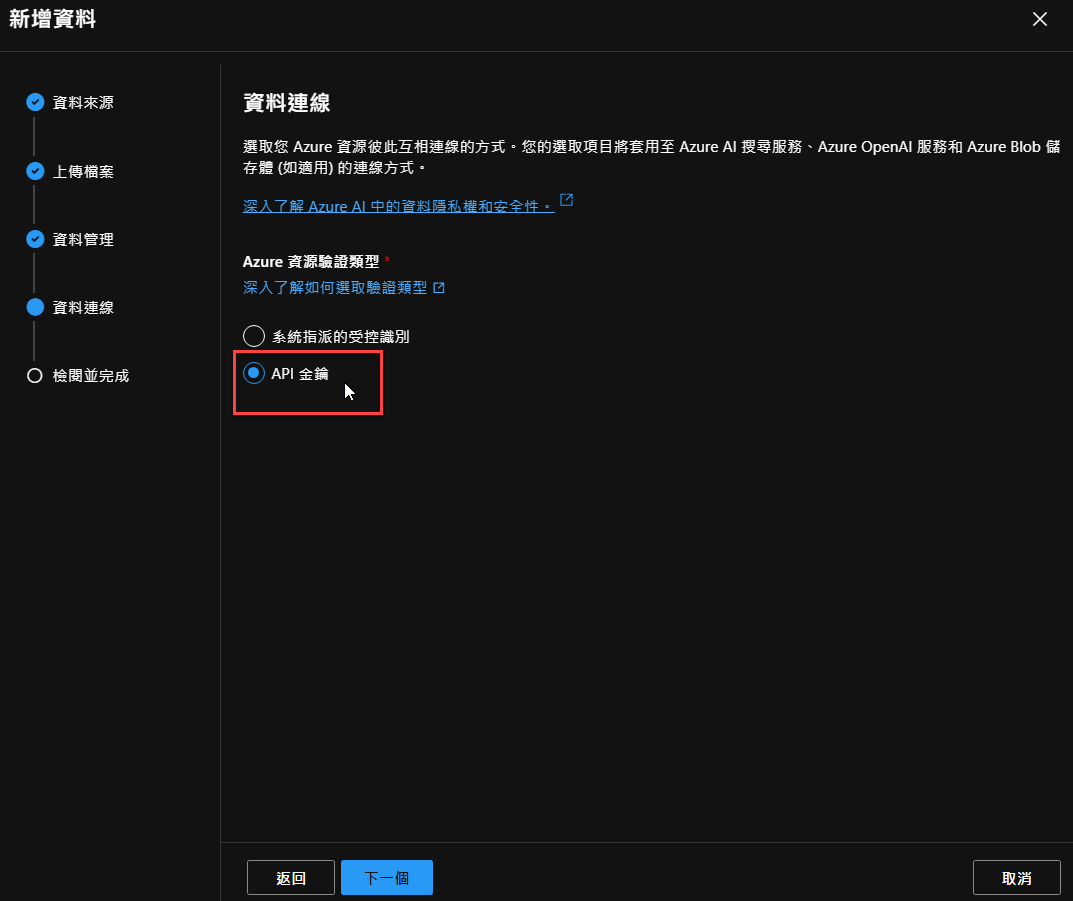
按下『下一個』之後,出現選擇資源驗證方式,請選擇『API金鑰』:
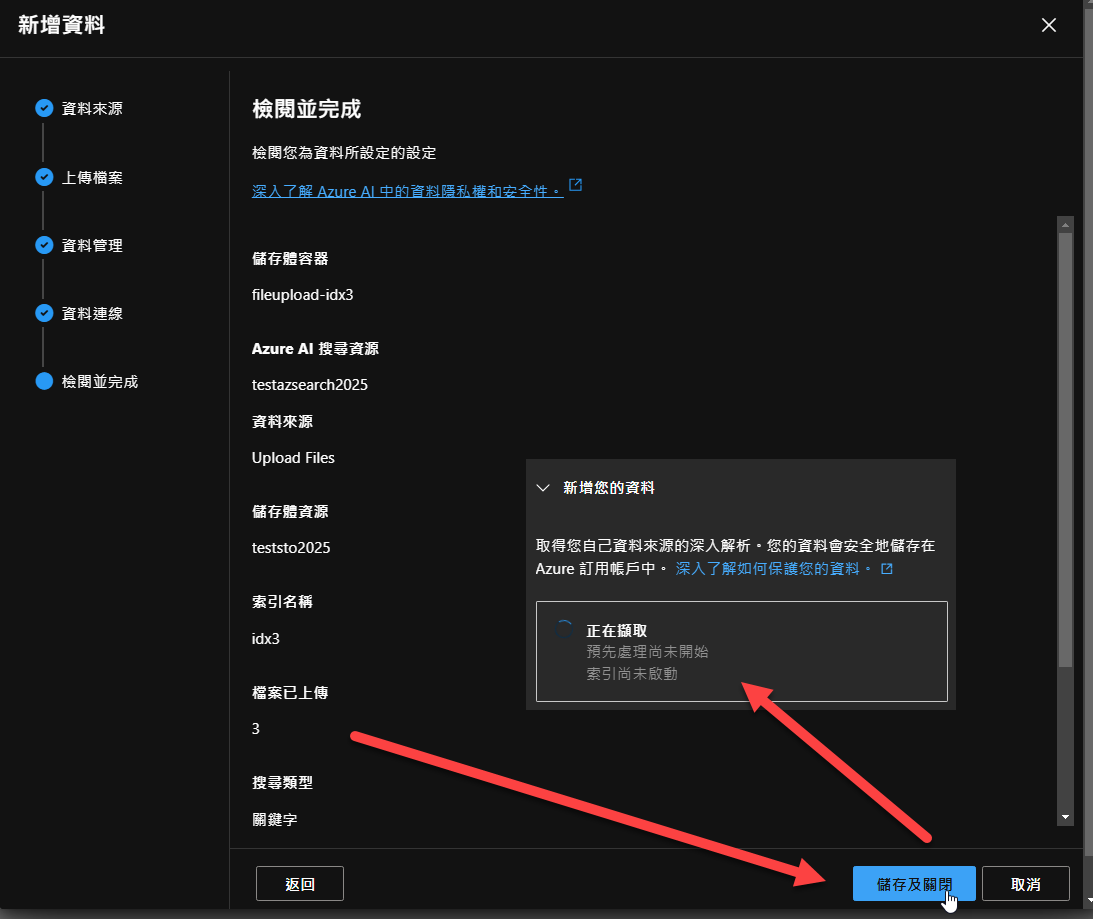
最後會出現檢閱畫面,確定設定無誤之後,按下『儲存及關閉』,接著,會出現『正在擷取』的訊息,這表示 Azure AI Search 正在索引您上傳的檔案:
完成之後,你會看到底下畫面:
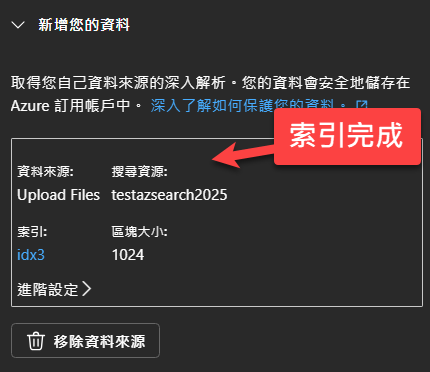
這表示你可以正常使用了。
我們剛才上傳的文件,是三份與教育訓練有關的PDF文件,透過這個機制,你現在詢問AI,它會優先搜尋剛才上傳的PDF中的資料,作為回應的基礎(而非讓LLM自己回覆):
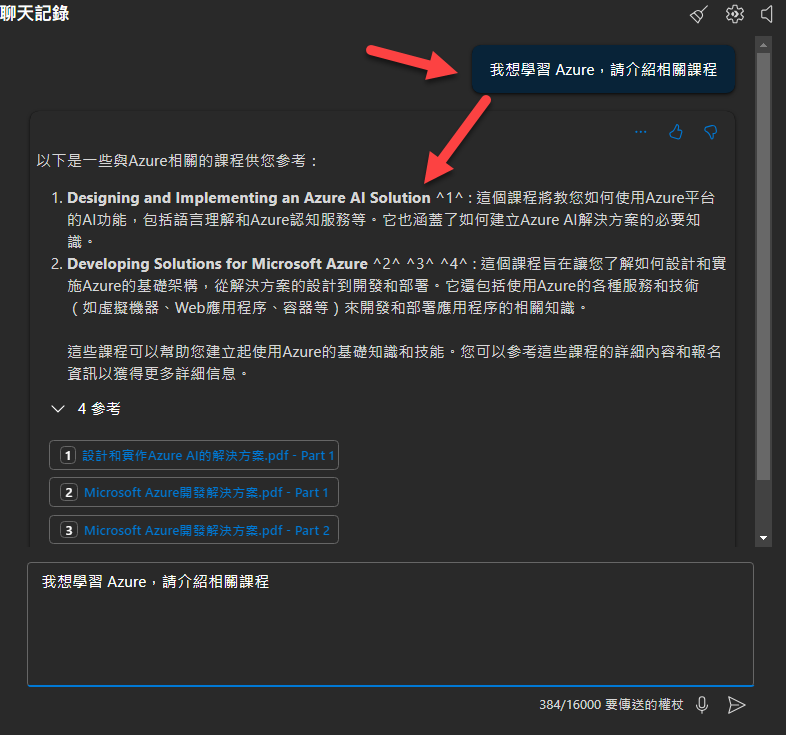
如此一來,使用者可以輕鬆地將企業內的自訂資料整合至模型中,提升回應的準確性和相關性,這功能無需具備深厚的技術背景,即可實現RAG(檢索增強生成),非常適用於知識庫問答、企業內部搜尋及 AI 助理等應用,讓更多使用者能夠利用 AI 技術滿足特定需求。





留言