使用LM Studio輕鬆在本地端以API呼叫大語言模型(LLM)
最近上課常被問到,如何在地端環境搭建出大語言模型(LLM),並且呼叫其API。
一開始我不太理解為何會有這樣的需求(因為在地端自行搭建運行LLM的成本不一定比較低,即便可能比較安全),但被問多了,也就開始遍尋相關的解決方案,看看有沒有什麼最簡單的方式,可以讓開發人員在地端測試大語言模型?
後來我選擇 LM Studio ,它就是一款設計來運行大型語言模型(LLM)的平台,有個算是挺優雅的整合環境,讓一般 end-user 或開發人員,都可以輕易地在 local 端進行模型的部署和測試。
LM Studio 本身支援多種模型架構和框架,當然,最重要的是,它是免費的。
下載安裝都很容易,我就不多說。
安裝好之後,你可以看到首頁中已經呈現了許多 Hugging Face上的模型:
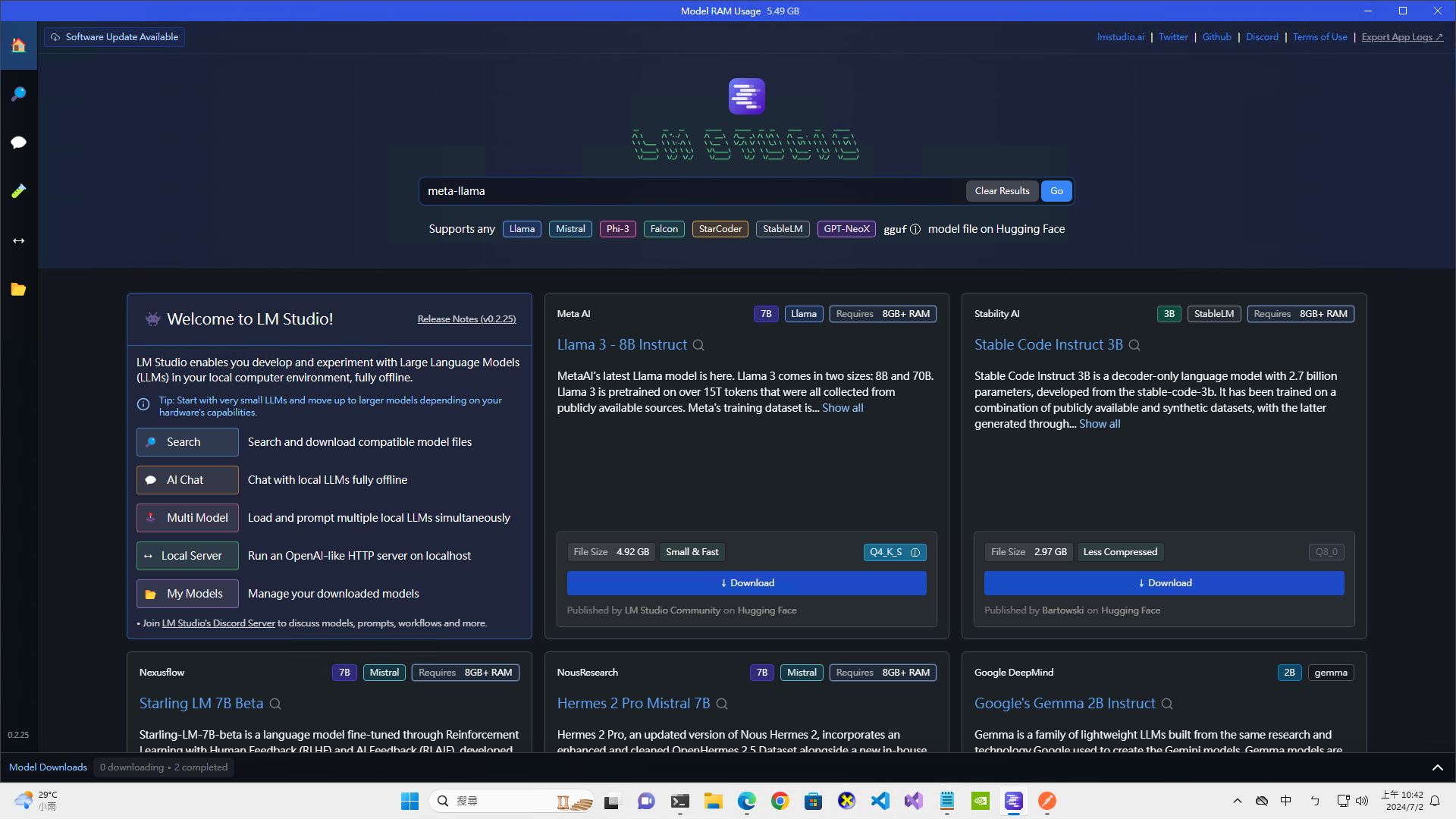
這顯然是因為Hugging Face是大部分免費開源模型的集散地。
你可以搜尋自己喜歡的模型,透過LM Studio下載到local之後,就可以直接載入(下圖一):
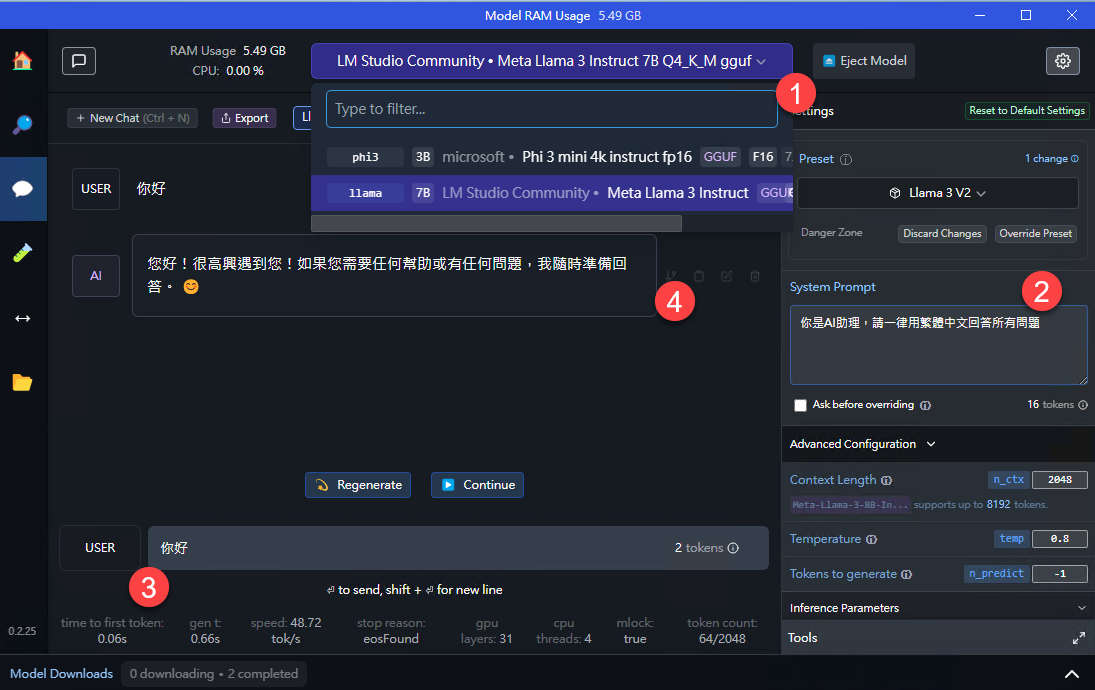
隨手設定一下 system prompt(上圖二),然後,就可以直接對談了。(上圖三)
LM Studio會使用你的GPU進行運算(如果有的話),你會發現,原來有好的設備(GPU),運行的速度可以如此之快。
Local Server
對於開發人員來說,它還有個超級更友善的功能。
LM Studio本身還提供一個 local server,可以幫你把模型包裹起來讓你直接透過API呼叫該模型的功能,例如:
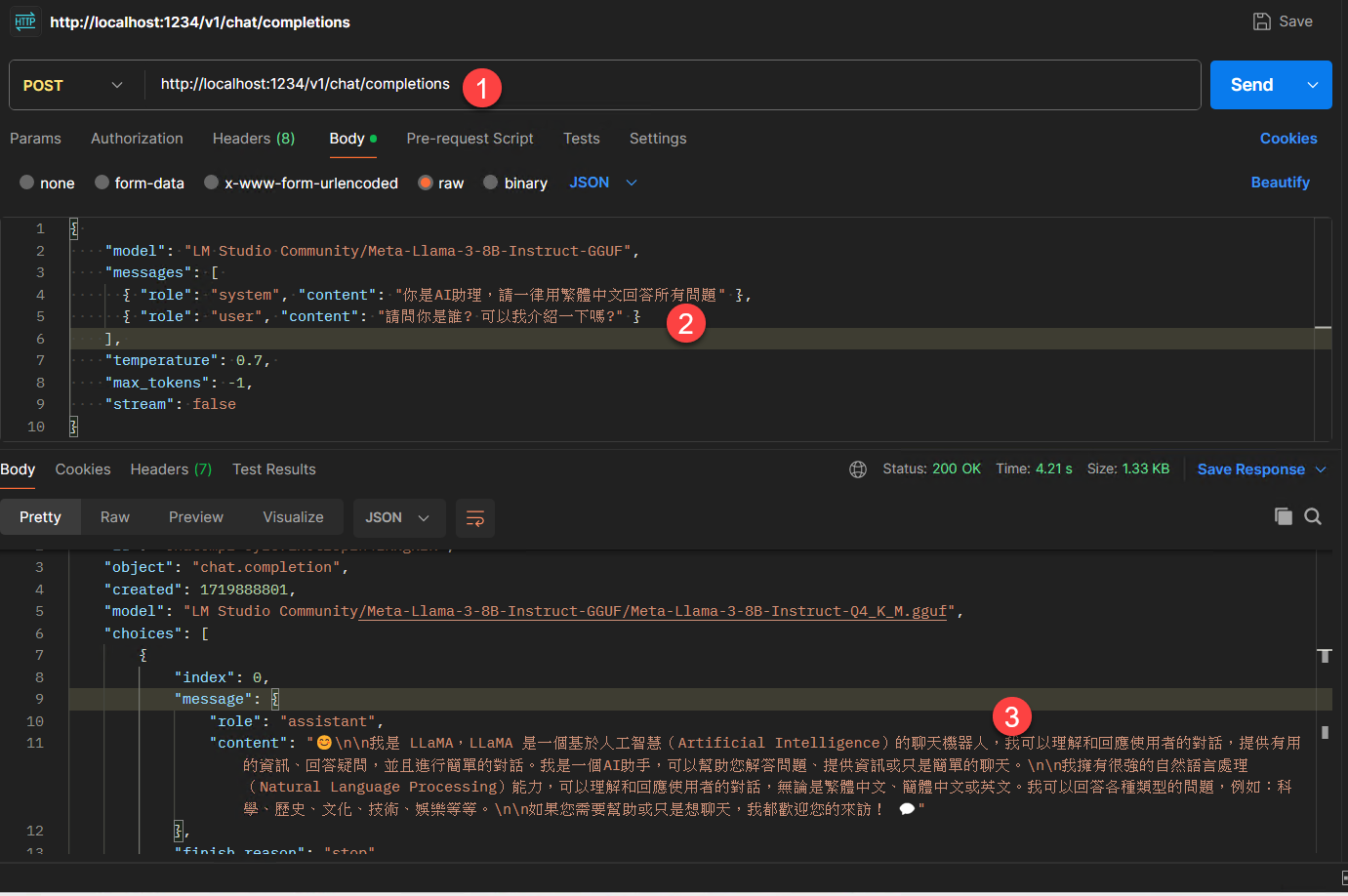
上圖是我們開啟 LM Studio中 Local Server功能後的結果,你可以透過 localhost 的 1234 port 來呼叫這個被 LM Studio 運行起來的大語言模型。(有沒有發現,我們用的也是 chat/completions API)
透過Postman簡單提供一下 JSON Body:
{
"model": "LM Studio Community/Meta-Llama-3-8B-Instruct-GGUF",
"messages": [
{ "role": "system", "content": "你是AI助理,請一律用繁體中文回答所有問題" },
{ "role": "user", "content": "請問你是誰? 可以我介紹一下嗎?" }
],
"temperature": 0.7,
"max_tokens": -1,
"stream": false
}
你就可以呼叫LLM,並且輕鬆得到回應:
{
(...略...)
"model": "LM Studio Community/Meta-Llama-3-8B-Instruct-GGUF/Meta-Llama-3-8B-Instruct-Q4_K_M.gguf",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "😊\n\n我是 LLaMA,LLaMA 是一個基於人工智慧(Artificial Intelligence)的聊天機器人,我可以理解和回應使用者的對話,提供有用的資訊、回答疑問,並且進行簡單的對話。我是一個AI助手,可以幫助您解答問題、提供資訊或只是簡單的聊天。\n\n我擁有很強的自然語言處理(Natural Language Processing)能力,可以理解和回應使用者的對話,無論是繁體中文、簡體中文或英文。我可以回答各種類型的問題,例如:科學、歷史、文化、技術、娛樂等等。\n\n如果您需要幫助或只是想聊天,我都歡迎您的來訪! 💬"
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 51,
"completion_tokens": 167,
"total_tokens": 218
}
}
要開啟這個功能,你只需要點選(下圖1)按鈕啟動 Local Server (當然模型得先載入)即可,它還有curl 和 python 的範例(下圖2),你說貼心不貼心?
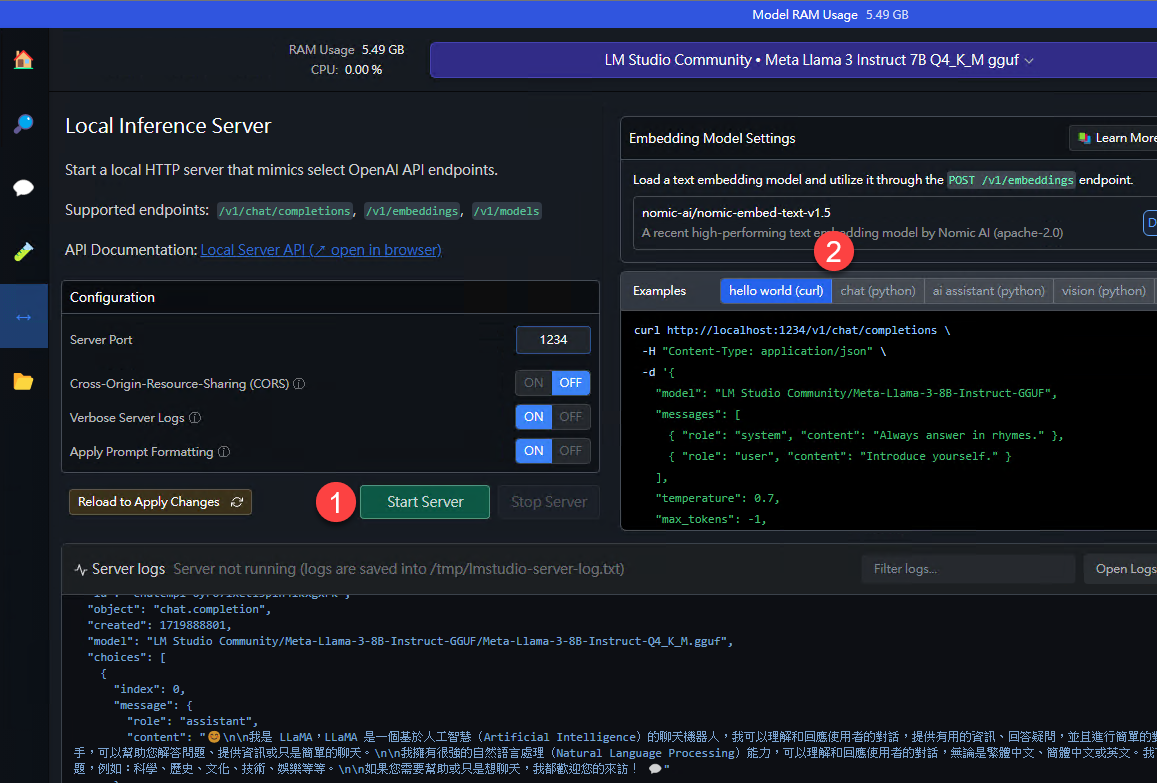
上圖是 LM Studio 運行 Local Server 的畫面,有沒有很方便?
如果你有強大的 GPU,對在 Local 運行LLM模型有興趣,我覺得它會是一個挺好的起點。




留言