[經驗分享]如何用VS Online及Scrum帶領兩岸三地團隊進行專案開發與管理 - (八) 重新對應Backlogs與Feature之間的關係,以及專案時程的推估
先前我們在這一篇當中,曾經介紹過如何從Features展開Backlogs,但也有非常多的狀況是直接產生(建立)Backlogs,這時候我們就有可能需要重新連結(對應)Backlogs與Feature之間的關係。在這一篇當中,我們來看看這個部分。
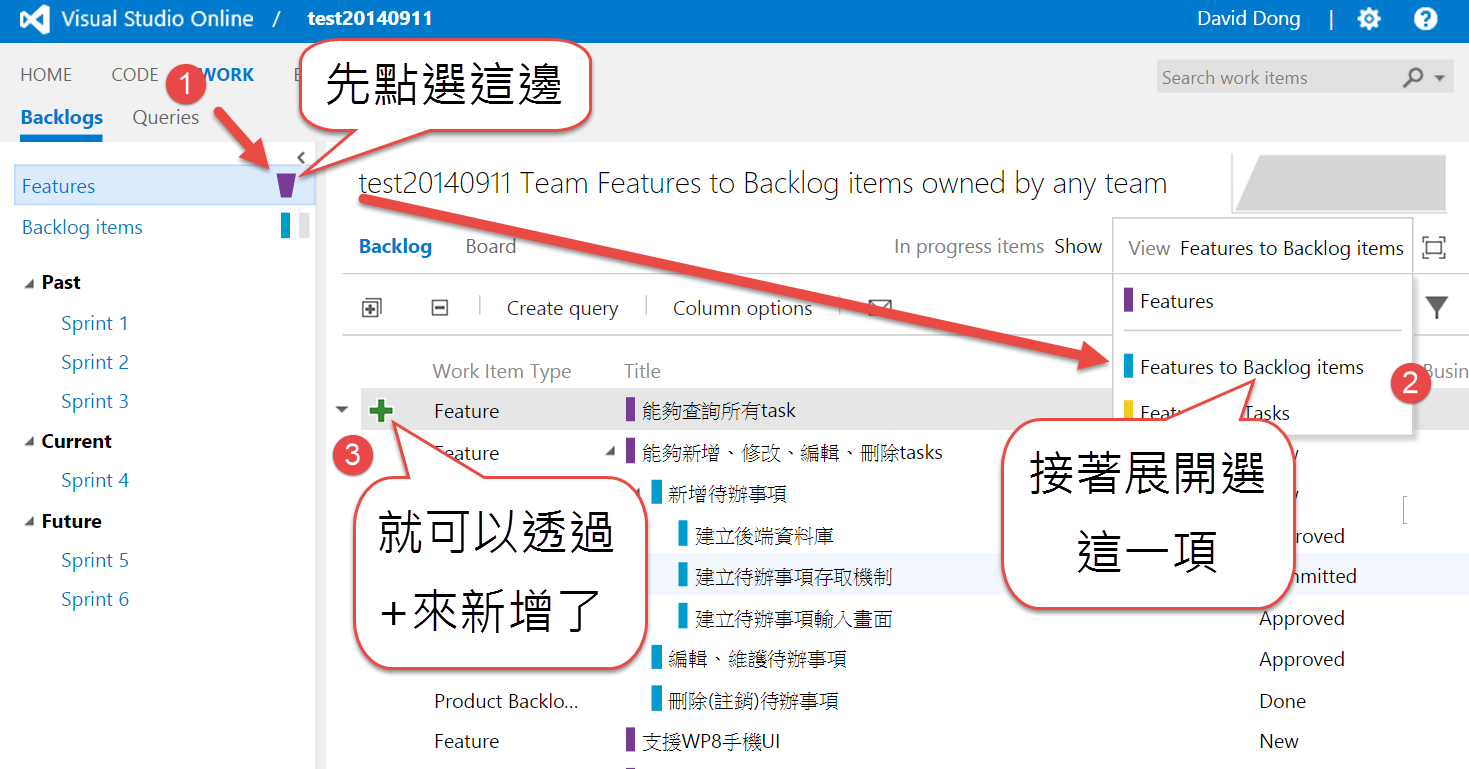
前面說過,你可以從Features展出Backlogs,這部分實際上操作時很簡單,你只需要在Features畫面中,依照底下的方式,就可以透過『+』從Features以展開的方式來撰寫Backlogs了。
但如果你的Backlogs是獨立寫好的,或是先寫了Backlogs,後來想要讓它歸屬於某一個Features,或是調整Backlogs的Features,可以怎麼做呢?請參考下圖:
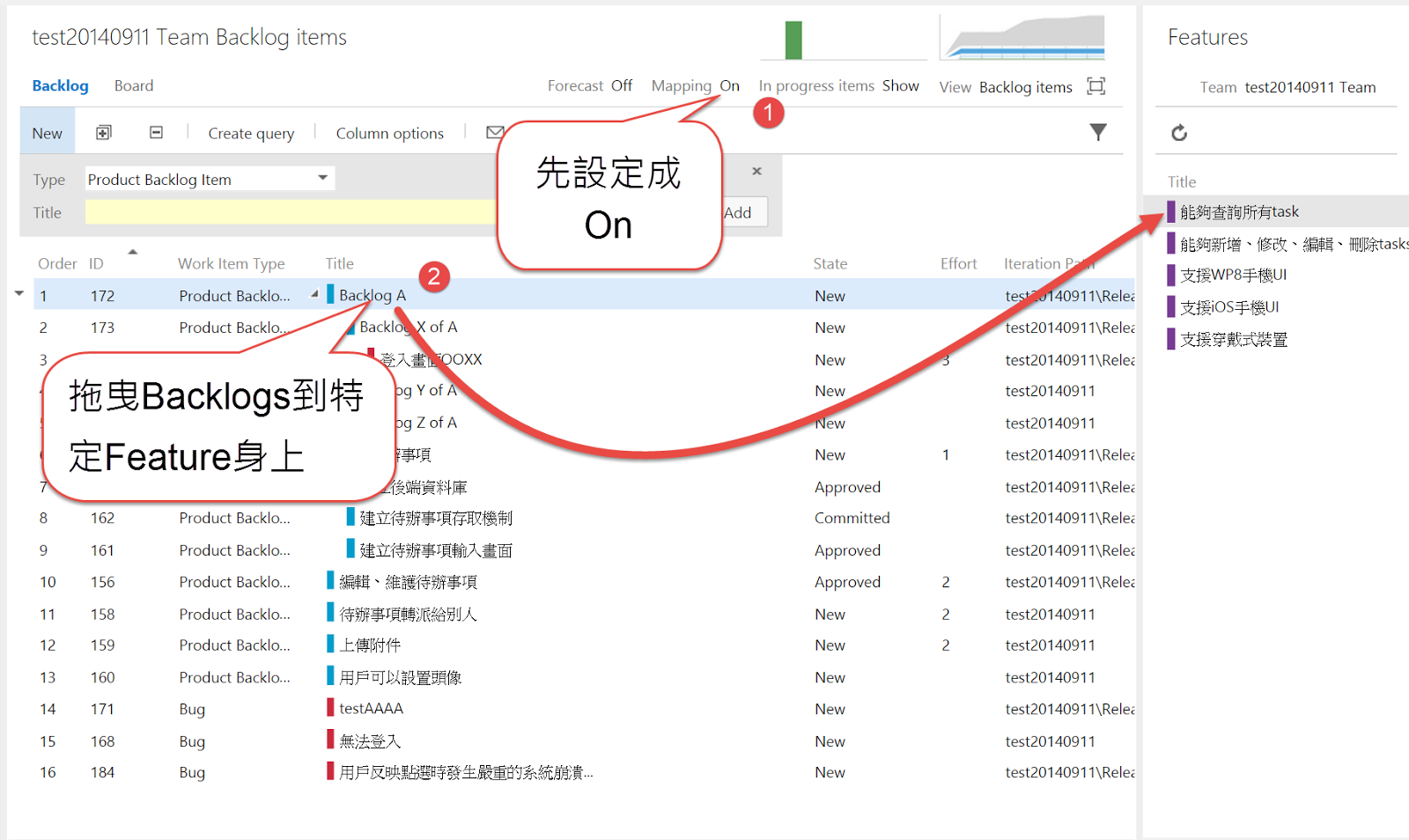
你可以先把Backlogs與Features的Mapping打開,即可拖曳特定Backlog到特定的Feature身上,以建立(或修改)兩者之間的關係。
此外,如果你觀察Product Backlogs的輸入畫面,會看到畫面右上部分,有一個forcase,可將其設為On,接著,會出現一個Forecasting Velocity讓你輸入調整(每個Sprint的工作量),設定後,即可看到如下圖的預估:
 你會發現,系統已經參考了我們輸入的參考工作量,依照Backlogs的順序,計算出會大致落在哪一個Sprint ,這個功能非常的好用,能夠讓客戶一目了然的知道特定的Backlogs大約會何時開始開發。
你會發現,系統已經參考了我們輸入的參考工作量,依照Backlogs的順序,計算出會大致落在哪一個Sprint ,這個功能非常的好用,能夠讓客戶一目了然的知道特定的Backlogs大約會何時開始開發。
但請留意一下這張圖,坦白說這張圖乍看之下不是很容易理解,所以我特別用藍底白字的箭頭,標註了一下Sprint。你會發現,編號1,2,3這三個Backlogs,是屬於Sprint 6進行開發的,而編號6,7,8,9則是屬於Sprint 8進行開發的。特別標註是因為,如果你把藍底白字的箭頭拿掉,你可能會以為編號3,4兩個backlog items是屬於Sprint 6,而編號5,6,7,8的backlog items是屬於Sprint 7,那可就誤會大了。
本篇收錄自 - 『敏捷開發專案管理與架構設計實務』
前面說過,你可以從Features展出Backlogs,這部分實際上操作時很簡單,你只需要在Features畫面中,依照底下的方式,就可以透過『+』從Features以展開的方式來撰寫Backlogs了。
但如果你的Backlogs是獨立寫好的,或是先寫了Backlogs,後來想要讓它歸屬於某一個Features,或是調整Backlogs的Features,可以怎麼做呢?請參考下圖:
你可以先把Backlogs與Features的Mapping打開,即可拖曳特定Backlog到特定的Feature身上,以建立(或修改)兩者之間的關係。
此外,如果你觀察Product Backlogs的輸入畫面,會看到畫面右上部分,有一個forcase,可將其設為On,接著,會出現一個Forecasting Velocity讓你輸入調整(每個Sprint的工作量),設定後,即可看到如下圖的預估:
但請留意一下這張圖,坦白說這張圖乍看之下不是很容易理解,所以我特別用藍底白字的箭頭,標註了一下Sprint。你會發現,編號1,2,3這三個Backlogs,是屬於Sprint 6進行開發的,而編號6,7,8,9則是屬於Sprint 8進行開發的。特別標註是因為,如果你把藍底白字的箭頭拿掉,你可能會以為編號3,4兩個backlog items是屬於Sprint 6,而編號5,6,7,8的backlog items是屬於Sprint 7,那可就誤會大了。
本篇收錄自 - 『敏捷開發專案管理與架構設計實務』





留言